
フロントエンド IP リソースの作成
IP 転送を無効にして Google Cloud ロードバランサーを使用する場合 ( Google Cloud – 内部ロードバランサーの使用) の「IP転送を無効にする」セクションを参照)、ロードバランサーフロントエンドに関連付けられた IP アドレスは、各バックエンドサーバーのローカルネットワークインターフェースにネットワークマスク /32(255.255.255.255)を使用して追加する必要があります。
これらの構成では、ロードバランサーのフロントエンド IP アドレスは、クラウドエージェントプロセスによってネットワークインターフェースに自動的に 追加されることはありません 。代わりに、各バックエンドサーバーのゲストオペレーティングシステム内に手動で追加する必要があります。これを実現する最も簡単な方法は、ロードバランサーの各フロントエンド IP アドレスに LifeKeeper IP リソースを作成し、次のセクションで作成する LB Health Check リソースの依存関係として追加することです。
IP リソースの作成 の手順に従って、次のパラメーターを使用して、ロードバランサーの各フロントエンドIPアドレスにIPリソースを作成および拡張します。
| Create Resource ウィザード | |
|---|---|
| Switchback Type | intelligent |
| Server | node-a |
| IP Resource | <Frontend IP Address> |
| Netmask | 255.255.255.255 |
| Network Interface | <Network Interface> |
| IP Resource Tag | <Resource Tag> |
| Pre-Extend ウィザード | |
| Target Server | node-b |
| Switchback Type | intelligent |
| Template Priority | 1 |
| Target Priority | 10 |
| Extend comm/ip Resource Hierarchy ウィザード | |
| IP Resource | <Frontend IP Address> |
| Netmask | 255.255.255.255 |
| Network Interface | <Network Interface> |
| IP Resource Tag | <Resource Tag> |
ロードバランサーのフロントエンド IP アドレスごとに IP リソースが作成されたため、ロードバランサーのヘルスチェックプローブに応答する LB Health Check リソースを作成できます。
LB Health Check リソースの作成
この例では、TCP ポート 54321 で Listen するサーバー node-a 上にサンプルの LB Health Check リソースを作成します。
- LifeKeeper GUIで、
![]() をクリックして Create Resource ウィザードを開きます。 「LB Health Check Kit」を選択します。
をクリックして Create Resource ウィザードを開きます。 「LB Health Check Kit」を選択します。
 をクリックして Create Resource ウィザードを開きます。 「LB Health Check Kit」を選択します。
をクリックして Create Resource ウィザードを開きます。 「LB Health Check Kit」を選択します。
- Create Resource ウィザードに次の値を入力し、プロンプトが表示されたら [Create] をクリックします。
![]() アイコンは、デフォルトのオプションが選択されていることを示します。
アイコンは、デフォルトのオプションが選択されていることを示します。
 アイコンは、デフォルトのオプションが選択されていることを示します。
アイコンは、デフォルトのオプションが選択されていることを示します。| Switchback Type | Intelligent |
| Server | node-a |
| Reply daemon Port | 54321 |
| Reply daemon message | 空欄のままにします |
| LB Health Check Resource Tag | ilb-test-54321 |
リソースが作成され、正常にサービスが開始されたら、 [Next>] をクリックして Pre-Extend ウィザード に進みます。
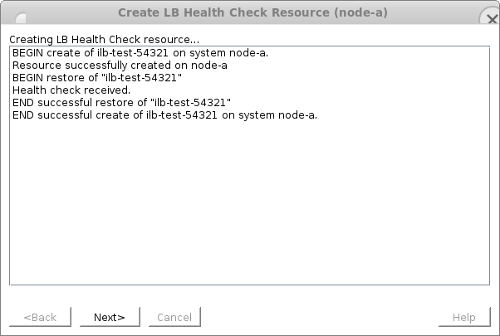
- Pre-Extend ウィザード に次の値を入力します。
![]() アイコンは、デフォルトのオプションが選択されていることを示します。
アイコンは、デフォルトのオプションが選択されていることを示します。
| Target Server | node-b |
| Switchback Type | Intelligent |
| Template Priority | 1 |
| Target Priority | 10 |
事前拡張チェックに合格したら、 [Next>] をクリックして、 Extend Resource Hierarchy ウィザードに進みます。
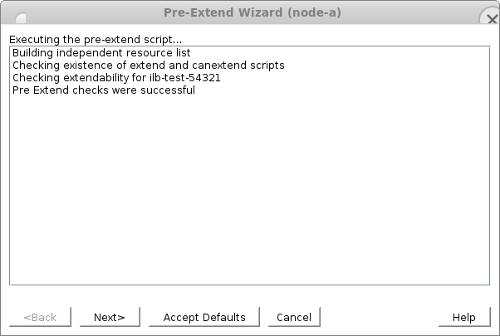
- Extend Resource Hierarchy ウィザードに次の値を入力し、プロンプトが表示されたら [Extend] をクリックします。
![]() アイコンは、デフォルトのオプションが選択されていることを示します。
アイコンは、デフォルトのオプションが選択されていることを示します。
| LB Health Check Resource Tag | ilb-test-54321 |
リソースが正常に拡張されたら、 [Finish] をクリックします。
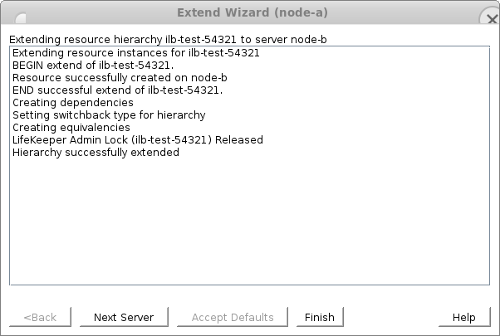
- LifeKeeper GUI に戻ると、新しく作成された ilb-test-54321 リソースが node-a でアクティブ、node-b でスタンバイであることがわかります。この状態では、ポート 54321 で TCP ヘルスチェックを実行する TCP ロードバランサーは、node-a を正常、node-b を異常として扱い、すべてのロードバランサートラフィックを node-a にルーティングします。このリソースは、保護されたアプリケーションとともにリソース階層に配置されると、ロードバランサーのトラフィックが常に、アプリケーションが現在実行されているサーバーにルーティングされるようにします。

LB Health Check リソースの依存関係としてフロントエンド IP リソースを追加する
IP 転送を無効にして Google Cloud ロードバランサーを使用する場合 ( Google Cloud – 内部ロードバランサーの使用 IP アドレスを保護する IP リソース(ネットワークマスク 255.255.255.255 を使用)は、LB Health Check リソースの依存関係として追加する必要があります。上記の「フロントエンドIPリソースの作成」セクションで作成したIPリソースごとに、次の手順を実行します。
- ilb-test-54321 リソースを右クリックし、ドロップダウンメニューから [Create Dependency…] を選択します。
- 子リソースタグ に、ロードバランサーのフロントエンドIPアドレスを保護するリソースを指定します。
- [Next>] をクリックして続行し、 [Create Dependency] をクリックして依存関係を作成します。
IP リソースが依存関係として追加されると、階層は次のようになります
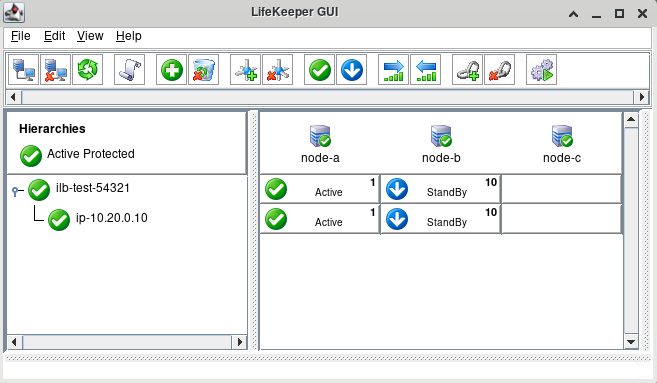
LB Health Check リソースのスイッチオーバーとフェイルオーバーをテストする
このセクションでは、node-a と node-b をバックエンドターゲットとして使用し、次のプロパティを持つ内部ロードバランサーを作成していると想定します。
- フロントエンド内部 IP: 10.20.0.10
- ポート 54321 での TCP ヘルスチェック
また、前のセクションで作成した ilb-test-54321 LB Health Check リソースは、現在 node-a でアクティブになっているとします。
便宜上、各サーバーのホスト名を返すだけの一時的な Apache Web サーバーをセットアップします。 node-aとnode-bの両方 で次のコマンドを実行します。SLES サーバーにインストールする場合は、コマンドを適宜調整してください(例:zypper install を使用)。
# yum install -y httpd # systemctl start httpd # echo $(hostname) > /var/www/html/index.html
続行する前に、node-a および node-b の TCP ポート 80 でトラフィックが許可されていることを確認してください。
次に、 ilb-test-54321 LB Health Checkリソースのスイッチオーバーおよびフェイルオーバー機能をテストします。
- ilb-test-54321 リソースが node-a でアクティブで node-b でスタンバイの場合、各サーバーで次のコマンドの出力を確認します。
[root@node-a ~]# curl http://10.20.0.10 node-a [root@node-b ~]# curl http://10.20.0.10 node-a
- node-a で以下のコマンドを実行します。
[root@node-a ~]# while true; do curl http://10.20.0.10; sleep 1; done
そして、 ilb-test-54321 リソースの node-b へのスイッチオーバーを開始します。スイッチオーバーが正常に完了したら、Ctrl-C(SIGINT)を使用して、node-a で実行中のコマンドを終了させます。
コマンドの出力は次のようになります。
…
node-a
node-a
node-a
[switchover occurs]
node-b
node-b
node-b
…
特に、ロードバランサーは、node-b へのルーティングを開始する前に、node-a へのトラフィックのルーティングを完全に停止する必要があります。スイッチオーバーポイント付近の出力が次のようになっている場合:
…
node-a
[switchover occurs]
node-b
node-a
node-b
node-a
node-b
node-a
node-b
node-b
node-b
…
ヘルスチェックのプロパティを編集して、バックエンドインスタンスが異常と判定されてロードバランサープールから削除される前に、ヘルスチェックスローブ間の時間を短くしたり、ヘルスチェックスローブの失敗の最小回数を減らしたりする必要がある場合があります。詳しくは、「ロードバランサーのヘルスチェックパラメータのチューニング」のセクションを参照してください。
- node-b で ilb-test-54321 リソースがアクティブになっている状態で、node-a で次のコマンドを実行します。
[root@node-a ~]# while true; do curl http://10.20.0.10; sleep 1; done
node-b を強制的に再起動して、 ilb-test-54321 リソースの node-a へのフェイルオーバーを開始します。
[root@node-b ~]# echo b > /proc/sysrq-trigger
フェイルオーバーが正常に終了したら,Ctrl-C(SIGINT)で node-a 上の実行中のコマンドを終了させます。
node-a でのコマンドの出力は以下のようなものになります。
…
node-b
node-b
node-b
[failover occurs]
node-a
node-a
node-a
…
この時点で、LB Health Check リソースの動作の基本的な検証は完了です。必要に応じて追加のテストを実行し、スイッチオーバーやフェイルオーバー時の LB Health Check リソースと保護対象のアプリケーション間の相互作用を検証します。LB Health Check リソースの機能テストが終了したら、node-a と node-b の両方で次のコマンドを実行して、一時的な Apache Web サーバーを削除することができます。
# systemctl stop httpd # rm -f /var/www/html/index.html # yum remove -y httpd
ロードバランサーヘルスチェックパラメーターのチューニング
ロードバランサーのデフォルトのヘルスチェックパラメーターは、ほとんどの一般的な状況で機能するはずですが、望ましいスイッチオーバー動作を実現するために、パラメーターを調整する必要がある場合があります。ユーザーがこれらのパラメーターを調整する必要があるかもしれない典型的な問題は2つあります。
- 値が低く設定されすぎているため、ロードバランサーが一時的なリソースの制約やネットワークの中断に対して敏感になりすぎている。
- 値が高く設定されすぎており、スイッチオーバー時にロードバランサーが新しいリソースホストへのトラフィックのルーティングを開始しても、以前のリソースホストは引き続き正常と判定される。
クラウドの負荷分散環境では、一般的に4つの主要なヘルスチェックパラメーターを調整することができます
- Health Check Interval(ヘルスチェック間隔) – ヘルスチェックサーバーがヘルスチェックプローブをバックエンドターゲットVMに送信する頻度
- Timeout(タイムアウト) – ヘルスチェックサーバーが、ヘルスプローブが失敗したと見なす前に応答の受信を待機する時間。
- ealthy Threshold(正常のしきい値) – バックエンドターゲットVMが正常と判定されるために、ヘルスチェックプローブが連続して正常な応答を受け取る必要がある回数。
- Unhealthy Threshold(異常のしきい値) – バックエンドターゲットVMが異常と判定されるために必要な、連続したヘルスチェックのプローブの失敗回数。
これらのパラメーターの詳細については、 Azure Load Balancer の正常性プローブ および Google Cloud – ヘルスチェックの概要 を参照してください。
これらのパラメータから、次の値を導出することもできます。
- 正常と判定されるまでの合計時間 = ヘルスチェック間隔 × (正常のしきい値 – 1) – サーバーとヘルスプローブサーバー間のネットワークレイテンシーが低いと仮定した場合の、正常なサーバーの最初のヘルスチェックプローブ後、ロードバランサーによって正常と判定されるまでの合計時間。 異常と判定されるまでの合計時間 = タイムアウト × 異常のしきい値 – 障害が発生したサーバーの最初のヘルスチェックプローブから、ロードバランサーによって異常と判定されるまでの合計時間。
これらのパラメーターの正確な値は各ユーザーの特定の環境によって異なりますが、いくつかの一般的なガイドラインを以下に示します。
タイムアウトまたは異常のしきい値のチューニングが低すぎると、一時的なVMリソースの制約または一時的なネットワークの問題に対して回復力のないロードバランサーになる可能性があります。たとえば、 タイムアウト = 1秒や 異常のしきい値 = 1回の失敗 などの極端な値を設定すると、ネットワークが数秒間応答しなくなった場合でも、バックエンドVMが異常と判定されます。これはクラウド環境では珍しいことではありません。ロードバランサーの構成が一時的でマイナーな問題に対してより回復力があるように、タイムアウトを適切な値(例:5秒)にしておくことをお勧めします。
Health Check Interval と Healthy Threshold の組み合わせが高すぎると、ロードバランサーがスイッチオーバーまたはフェイルオーバー後に新しいリソースホストへのトラフィックのルーティングを開始するのに必要以上に長い時間がかかり、アプリケーションの回復に時間がかかる可能性があります。ほとんどの場合、 Healthy Threshold = 2 回連続成功 を設定するのが適切です。
Timeout と Unhealthy Threshold の組み合わせが高すぎると、スイッチオーバー後にロードバランサーが前のリソースホストノードを異常と判断するのに十分な速さで反応せず、ラウンドロビン形式でアクティブサーバーとスタンバイサーバーの両方にロードバランサーのトラフィックがルーティングされる時間が発生することがあります。このような状況を回避するために、リソース階層を何度かスイッチオーバーしてデータを収集し、前のホストで LB Health Check リソースが Out-of-Service になってから新しいホストで In-Service になるまでの最短時間を決定することが推奨されます。
クラスタサーバー間で時刻が同期していると仮定すると、各サーバーの /var/log/lifekeeper.log を調べ、前のホストでの LB Health Check remove スクリプトの終了から新しいホストでのLB Health Check restore スクリプトの終了までの時間を決定することによって、この時間を求めることができます。この時間(秒)を Minimum LB Health Check Switchover Time (最小 LB Health Check スイッチオーバー時間)と呼ぶことにします。そこで、ロードバランサーのヘルスチェックパラメーターを以下のように設定することを推奨します。
異常と判定されるまでの合計時間 < 最小 LB Health Checkスイッチオーバー時間 + 正常と判定されるまでの合計時間
Timeout の値が Health Check Interval と同じになるように選択されている一般的な状況(例えば、両方とも5秒に設定されている)では、推奨は次のようになります。
異常のしきい値 < ( 最小 LB Health Checkスイッチオーバー時間 / タイムアウト ) + 正常のしきい値 – 1
例として、ロードバランサーのヘルスチェックパラメーターを、 ヘルスチェック間隔 = タイムアウト = 5秒 および 正常のしきい値 = 2回連続成功 で設定したとします。リソース階層を使用して繰り返しスイッチオーバーテストからデータを収集することにより、経験的に、 最小 LB Health Check スイッチオーバー時間 = 20秒 であることがわかります。上記の推奨事項を参考に 異常のしきい値 を選択すると、以下のようになります。
異常のしきい値 < (20 / 5) + 2 – 1 = 5
このことから、2 ~4 回の連続した失敗を異常のしきい値として選択するのが妥当でしょう。スイッチオーバーテスト中に、ロードバランサーがスイッチオーバー後すぐに前のホストを異常と判定していないことがわかったら、より低い値(2 や3 など)を選択します。もしテスト中に、ロードバランサーが一時的なサーバーやネットワークの問題が原因で、現在のリソースホストを定期的に異常と判定していることがわかった場合は、より高い値(3または4 など)を選択します。この例では、 異常のしきい値 = 3回連続失敗 を選択するのが妥当かもしれません。
このトピックへフィードバック