
ここでは DRBD を用いた3ノードディザスターリカバリーの構成例を説明します。
概要
以下の AWS クラウドでの3ノード構成例では Region A をメインサイトとして、NodeA1, NodeA2 が動作し、Region B をバックアップサイトとして、NodeB1 が動作しています。NodeA1 と NodeA2 間は DRBD の同期接続でデータの信頼性を確保しつつ、NodeA1 と NodeB1, NodeA2 と NodeB1 間は DRBD の非同期接続でメインサイトのアプリケーションへの影響を最小限に保ちます。クライアントはメインサイトのアクティブノード に Route53 を用いた FQDN 名でアクセスします。
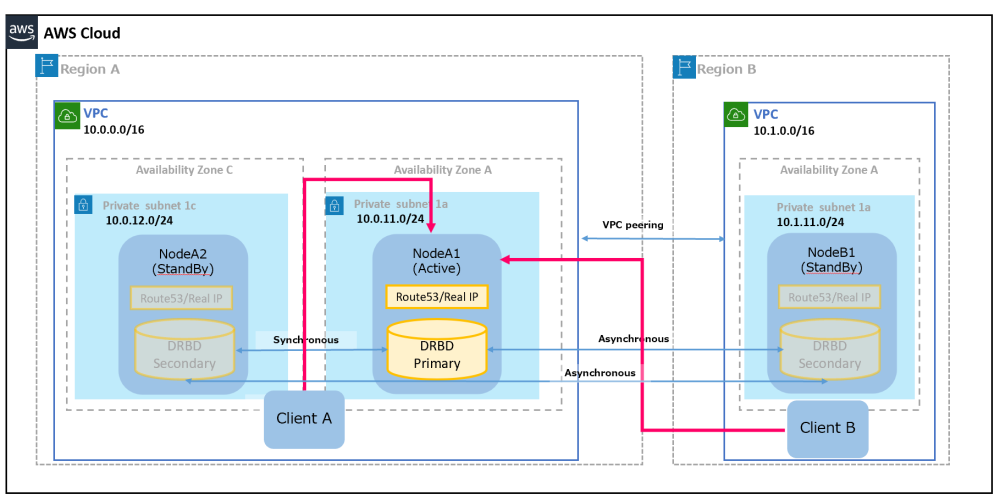
メインサイトがダウンした場合は、NodeA1, NodeA2 が停止するので、バックアップサイトの NodeB1 へアクセスして、災害復旧まで備えます。
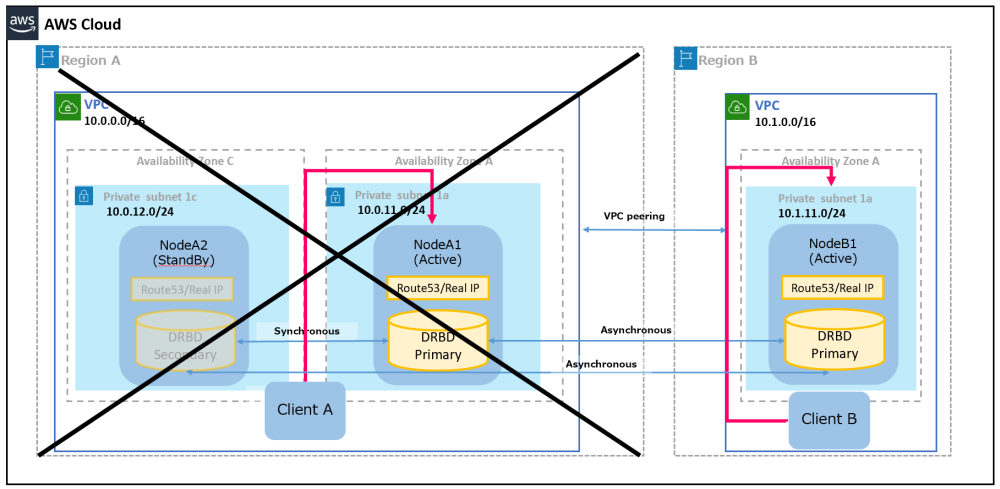
メインサイトがダウンしたときにすばやくバックアップサイトにアクセスできるよう常にメインサイト以外にもクライアントを準備しておくことを推奨します。
バックアップサイトでのサービス起動
バックアップサイトでのサービス自動起動
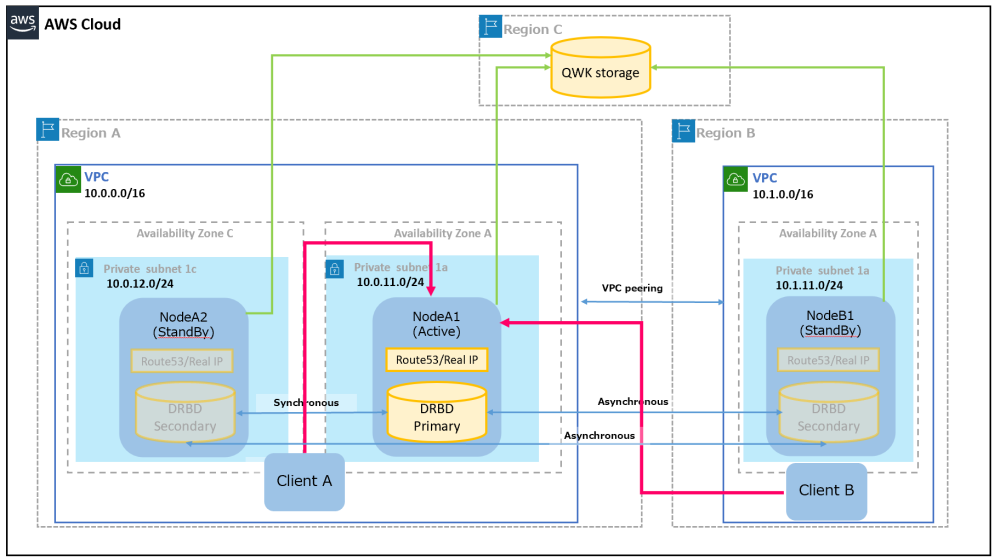
一般に3ノード構成では、Quorum/Witness の majority モードを使用することで、スプリットブレインを防止します。ただし、Disaster Recovery 構成ではメインサイトの2台が停止するので、バックアップサイトのノード1台では Quorum を持つことができず、自動起動はできません。この場合、storage モードを使用することでメインサイトの2台が停止しても、バックアップサイトのノードにフェイルオーバーして、サービスをすばやく継続できます。storage としては、例えばメインサイト、バックアップサイトとは別のリージョンに Amazon S3 を準備しておきます。Quorum/Witness 設定なしでも自動で起動しますが、ネットワークが分断した場合(メインサイトは生きているが、クラスタノード間のネットワークが切断)はスプリットブレインになる可能性もあるので、Quorum/Witness の使用を推奨します。
バックアップサイトでのサービス手動起動
Quorum/Witness の majority モードを使用することで、スプリットブレインを防止しつつ、メインサイトダウン時には手動で、バックアップサイト側でサービスを起動できます。Quorum を持っていないのでフェイルオーバーによる自動起動はできませんが、サービスを手動で起動することはできますので、バックアップサイトのノードにアクセスして手動で起動します。
災害復旧後の切り戻し
メインサイトが復旧し、バックアップサイトからサービスをメインサイトに戻すのには、自動で戻す方法と手動で戻す方法があります。以下の例では awsnode1, awsnode2 がメインサイト、awsnode11 がバックアップサイトにあるノードとします。
自動で戻す方法
最上位のリソースの switchback タイプを automatic に設定することで、メインサイトが復旧後自動的にサービスをメインサイトで稼働させることも可能です。メインサイトのノードのうち、 switchback タイプを automatic に設定していないほうのノードを先に立ち上げ、その後(同期中でも OK)設定しているほうのノードを立ち上げます。ただし、同期完了まで DRBD はバックアップサイトのものに書き込みますし、メインサイトの2台のノードへの同期がバックアップサイトのノードから同時に始まりますので、同期完了後のほうがよいでしょう。
Dec 12 16:38:14 awsnode1 lkswitchback[4292]: INFO:lkswitchback::pgsql:010084:lkswitchback(awsnode11): Attempting automatic switchback of resource "pgsql"同期中に awsnode1 で restore した場合、ローカルディスクは Inconsistent ですが同期完了までは awsnode11 のディスクに書き込むことで Primary になれます。
[root@awsnode1 ~]# drbdsetup status
lk0 role:Primary
disk:Inconsistent
awsnode2 role:Secondary
replication:PausedSyncS peer-disk:Inconsistent done:78.44 resync-suspended:peer,dependency
awsnode11 role:Secondary
replication:SyncTarget peer-disk:UpToDate done:7.42手動で戻す方法
- メインサイトの1台のノードを立ち上げます。DRBD が同期されるのを待ちます。
[root@awsnode1 ~]# drbdsetup status
lk0 role:Secondary
disk:Inconsistent
awsnode11 role:Primary
replication:SyncTarget peer-disk:UpToDate done:14.24
awsnode2 connection:Connecting
[root@awsnode1 ~]# drbdadm status
lk0 role:Secondary
disk:UpToDate
awsnode11 role:Primary
peer-disk:UpToDate
awsnode2 connection:Connecting- 1台目の同期完了後2台目を立ち上げます。メインサイトの1台目を先に立ち上げておくことにより、メインサイトの1台目からの同期も可能になり、より早く同期が完了するかもしれません(注:どちらから同期されるかは環境に依存します)。
[root@awsnode2 ~]# drbdadm status
lk0 role:Secondary
disk:Inconsistent
awsnode1 role:Secondary
replication:SyncTarget peer-disk:UpToDate done:70.13
awsnode11 role:Primary
replication:PausedSyncT peer-disk:UpToDate done:68.54
resync-suspended:dependency
[root@awsnode1 ~]# drbdadm status
lk0 role:Secondary
disk:UpToDate
awsnode11 role:Primary
peer-disk:UpToDate
awsnode2 role:Secondary
replication:SyncSource peer-disk:Inconsistent done:85.20- 同期完了後、メインサイトにサービスをスイッチオーバーします。なお、既存の問題 により、メインサイト2台が立ち上がった後でないとスイッチオーバーできません。
[root@awsnode1 ~]# lkcli resource restore --tag <service_tag>障害発生時の通知
LifeKeeper のイベント通知機能では、特定のイベントが起きたときに通知を送信できます。詳細は、SNMP による LifeKeeper イベント転送 をご覧ください。
各種パラメータの調整
LifeKeeper, DRBD にはいくつか調整可能なパラメータがあります。デフォルトでも特に問題ありませんが、使用する環境によって調整したほうがよいケースもあります。ここではいくつかのパラメータについて説明します。
Heartbeat, Confirm failover
- Heartbeat
特に最初から変更する必要性はなく、メインサイトとバックアップサイトの間に 15 秒以上のダウンタイム期間が定期的に発生する場合、LCMHBEATTIME(デフォルト値 5)、LCMNUMHBEATS(デフォルト値3)の値を増やして改善するか確認します。
- Confirm failover
confirmso! フラグがノード毎に設定され からのノードフェイルオーバー時に確認メッセージが表示されます。メインサイトダウン以外での不意のバックアップサイトへのフェイルオーバーを防ぐため、バックアップサイトへのノードフェイルオーバーは確認してからがよい場合に設定します(リソースフェイルオーバーには影響ありません)。
WANの設定 もご覧ください。
DRBD パラメータ
DRBD リソースではいくつかのDRBD パラメータが設定されています。
動的同期速度(c-fill-target, c-min-rate, c-max-rate)
これらのパラメーターは DRBD の動的同期速度の調整に使われます。動的同期速度調節機能は、ネットワークとディスク帯域を c-max-rate 以下の値で最大限確保しようとします。また、以下の場合には同期速度を減速させます。
- c-fill-target の量よりも多くの同期リクエストがあるとき
- アプリケーション I/O (書き込みまたは読み込み)を検出し、推定同期速度が c-min-rate を上回るとき
c-fill-target パラメーターはどのくらいの量の再同期データを DRBD 実行中に常に持つかを定義します。一般に、c-fill-target の初期値は帯域幅遅延積(Bandwidth Delay Product、BDP)の2倍がよいと言われています。
https://linbit.com/drbd-user-guide/drbd-guide-9_0-ja/#s-configure-sync-rate-variable
BDPは帯域幅とラウンドトリップタイム (RTT) の積であり 、一定時間におけるネットワーク上のデータ量の最大値、すなわち送信済みであるものの肯定応答を受け取っていないデータ量と等しくなります。この値を増やすことは送信したがまだ応答を受け取ってないデータが増えることを意味します。送信中のデータがc-fill-targetを超えないようにデータ送信量を減らします。
これらの値は、DRBD リソース作成時、c-fill-target が 1MB(2048 sectors, 1 sector=512bytes), c-min-rate が 20MB/s, c-max-rate が 500MB/s に設定されています。例えば、AWS の東京リージョンと大阪リージョン間で、ping で RTT の平均値が 1.8ms、iperf3 で帯域幅が4.5 Gbits/s = 562 MBytes/sだということが分かったとします。するとBDPは、
BDP = 562 MBytes/s * 0.0018 s = 1.0MBytesc-fill-target の初期値は BDP * 2 がよいので、c-fill-target は 2MB ぐらいでもよいかもしれません。
これらのパラメーターは GUI では設定できず、lkcli drbd options で設定します。直接 /etc/drbd.d/lk*.res ファイルを編集することはサポートされていません。
# lkcli drbd options --tag drbd-disk1 --entry c-fill-target --value 2M --host1 awsnode1 --host2 awsnode11 --sys awsnode1
# lkcli drbd options --tag drbd-disk1 --entry c-fill-target --value 2M --host1 awsnode2 --host2 awsnode11 --sys awsnode2固定同期速度(c-plan-ahead, resync-rate)
c-plan-ahead は DRBD が再同期速度の変化にどのくらい速く適応するかを定義します。DRBD リソース作成時は設定せず、デフォルト(20, 0.1 単位で2秒)を使っています。RTT の5倍以上に設定することが推奨されています。0 にすると動的同期機能が無効化され resync-rate で設定した値が固定値として使われます(DRBD リソース作成時は 166MB/s が設定されています)。
# lkcli drbd options --tag drbd-disk1 --entry c-plan-ahead --value 0 --host1 awsnode1 --host2 awsnode11 --sys awsnode1
# lkcli drbd options --tag drbd-disk1 --entry c-plan-ahead --value 0 --host1 awsnode2 --host2 awsnode11 --sys awsnode2送信バッファサイズ(sndbuf-size)
sndbuf-size は TCP 送信バッファサイズを指定します。DRBD リソース作成時は設定せず、デフォルト(0:自動調整)を使います。最大 10MB まで設定できます。リージョン間に距離があり遅延が大きい場合は最初から大きめに設定してもよいかもしれません。
# lkcli drbd options --tag drbd-disk1 --entry sndbuf-size --value 10M --host1 awsnode1 --host2 awsnode11 --sys awsnode1
# lkcli drbd options --tag drbd-disk1 --entry sndbuf-size --value 10M --host1 awsnode2 --host2 awsnode11 --sys awsnode2AHEAD/BEHIND モード(on-congestion, congestion-fill)
デフォルトでは TCP 送信バッファが一杯になると書き込みをブロックします。通常の使用であればバッファが一杯になることはほとんどありませんが、大きな書き込みを頻繁に行うと書き込みがブロックされ、アプリケーションのパフォーマンスに影響がでます。このようなケースが頻繫に起きる場合は、on-congestion でポリシーを pull-ahead にすることで、送信バッファが一杯になる前に AHEAD/BEHIND モードに切り替えて、ビットマップには記録するがレプリケーションを行わないモードに移行できます。十分なバッファが再び利用可能になると、ノードは対向ノードと同期を再開し、通常のレプリケーションに戻ります。バッファが一杯になってもアプリケーションの I/O をブロックしないという利点があるのですが、対向ノードの同期が大幅に遅れるという欠点もあります。また、再同期している間、対向ノードは inconsistent(不整合) になりその間はフェイルオーバーができなくなるため注意が必要です。なお、モードを切り替える閾値は、congestion-fill で指定し(デフォルト値は 0 でこの輻輳制御のメカニズムを無効にする)、sndbuf-size より小さい値を指定します。
# lkcli drbd options --tag drbd-disk1 --entry on-congestion --value pull-ahead -c --host1 awsnode1 --host2 awsnode11 --sys awsnode1
# lkcli drbd options --tag drbd-disk1 --entry on-congestion --value pull-ahead -c --host1 awsnode2 --host2 awsnode11 --sys awsnode2
# lkcli drbd options --tag drbd-disk1 --entry congestion-fill --value 9M --host1 awsnode1 --host2 awsnode11 --sys awsnode1
# lkcli drbd options --tag drbd-disk1 --entry congestion-fill --value 9M --host1 awsnode2 --host2 awsnode11 --sys awsnode2詳細は
https://linbit.com/man/drbd-9-0-ja/?linbitman=drbdsetup.8.html
をご覧ください。
このトピックへフィードバック