
This section describes an example of a three-node disaster recovery configuration using DRBD.
Overview
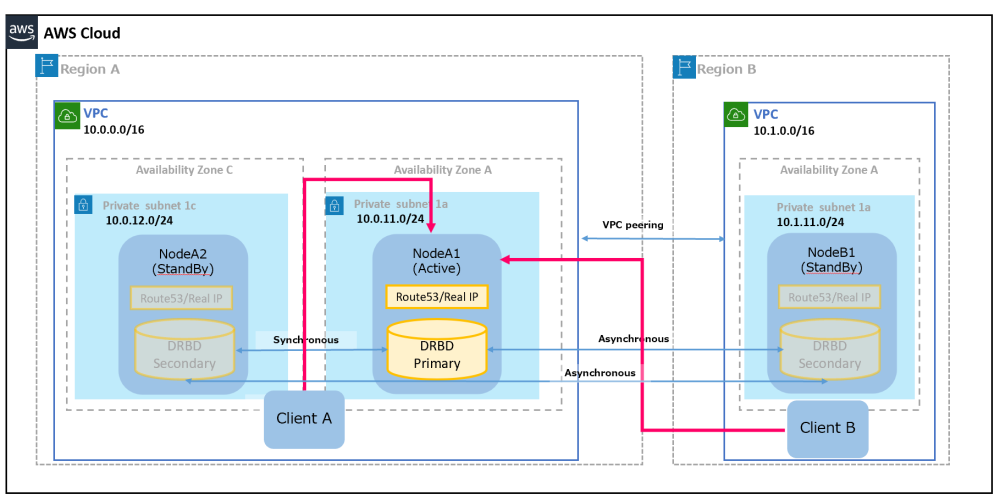
In the following example of a three-node configuration on the AWS cloud, Region A is the main site with NodeA1 and NodeA2 running, and Region B is the backup site with NodeB1 running. A synchronous DRBD connection between NodeA1 and NodeA2 ensures data reliability, while an asynchronous DRBD connection between NodeA1 and NodeB1, NodeA2 and NodeB1 minimizes the impact on applications on the main site. Clients access the active node on the main site with the FQDN name using Route53.
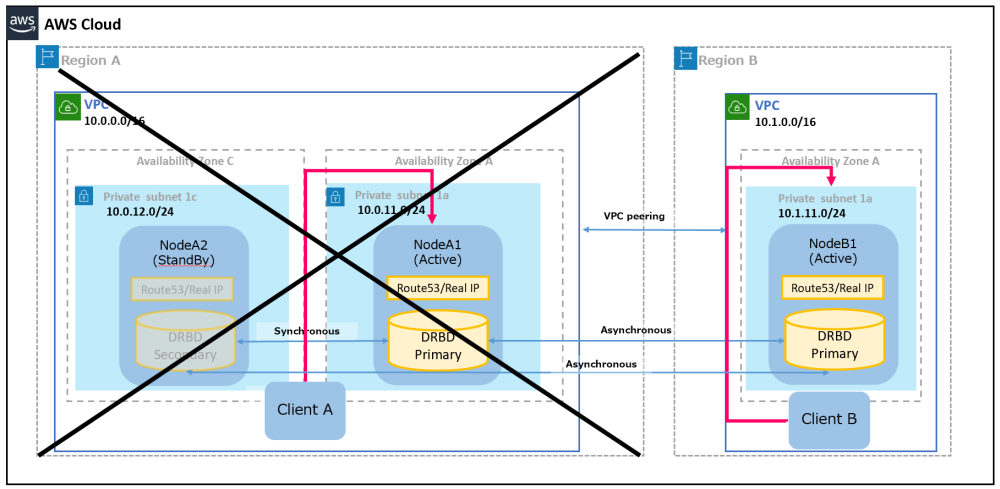
If the main site goes down, NodeA1 and NodeA2 will stop. However, you can access NodeB1 on the backup site to prepare for disaster recovery.
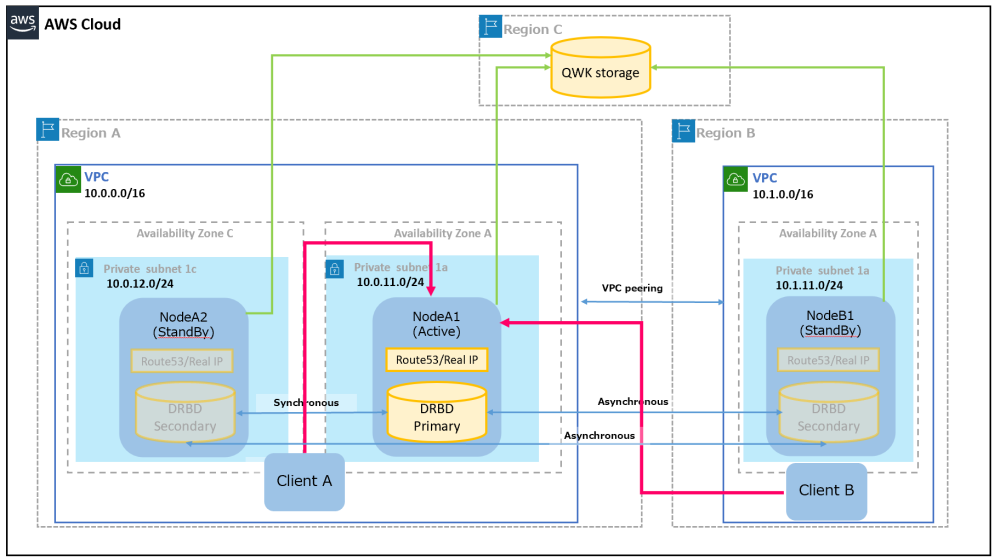
We recommend that you always have clients prepared at a backup site, in addition to the main site so that you can quickly access it if the main site goes down.
Starting a Service on the Backup Site
Automatic startup of a service on the backup site
In a three-node configuration, split-brain is typically prevented by using Quorum/Witness majority mode. However, in a disaster recovery configuration, since the two nodes on the main site will be down, the single node on the backup site will not constitute a quorum and will not be able to start automatically. In this case, the storage mode can be used to quickly failover to the node on the backup site and continue a service when the two nodes on the main site go down. Although it will start automatically without a Quorum/Witness configuration, it is recommended to use Quorum/Witness because a split-brain may occur in the event of a network disruption (the main site is alive, but the network between cluster nodes is disconnected).
Manually starting a service on the backup site
By using the Quorum/Witness majority mode, a service can be started manually on the backup site when the main site goes down, preventing split-brain. Since no Quorum is constituted on the backup site, automatic startup with failover cannot be performed. However, you can access the node on the backup site to start the service manually.
Switchback after disaster recovery
When the main site is restored, there are two ways to switchback the service from the backup site to the main site: automatically or manually. In the following example, awsnode1 and awsnode2 are the nodes on the main site and awsnode11 is on the backup site.
Automatic switchback
By setting the switchback type of the top-level resource to automatic, the service will automatically run on the main site once it is restored.
Start the node on the main site that does not have the switchback type set to automatic first. After that, start the node that has the switchback type set to automatic, even if it is still syncing. However, it is better to wait until after the synchronization is complete. This is because DRBD will write to the node on the backup site until the synchronization is complete, and the synchronization to the two nodes on the main site will start simultaneously from the node on the backup site.
Dec 12 16:38:14 awsnode1 lkswitchback[4292]: INFO:lkswitchback::pgsql:010084:lkswitchback(awsnode11): Attempting automatic switchback of resource "pgsql"If restore is performed on awsnode1 during synchronization, the local disk is in an inconsistent state, but it can become Primary by writing to the disk on awsnode11 until synchronization is complete.
[root@awsnode1 ~]# drbdsetup status
lk0 role:Primary
disk:Inconsistent
awsnode2 role:Secondary
replication:PausedSyncS peer-disk:Inconsistent done:78.44 resync-suspended:peer,dependency
awsnode11 role:Secondary
replication:SyncTarget peer-disk:UpToDate done:7.42Manual switchback
- Start one node at the main site and wait for DRBD to synchronize.
[root@awsnode1 ~]# drbdsetup status
lk0 role:Secondary
disk:Inconsistent
awsnode11 role:Primary
replication:SyncTarget peer-disk:UpToDate done:14.24
awsnode2 connection:Connecting
[root@awsnode1 ~]# drbdadm status
lk0 role:Secondary
disk:UpToDate
awsnode11 role:Primary
peer-disk:UpToDate
awsnode2 connection:Connecting- After synchronization of the first node is complete, start the second node. By starting the first node on the main site first, it is possible to synchronize from it which may complete the synchronization faster (Note: which node is synchronized first depends on the environment).
[root@awsnode2 ~]# drbdadm status
lk0 role:Secondary
disk:Inconsistent
awsnode1 role:Secondary
replication:SyncTarget peer-disk:UpToDate done:70.13
awsnode11 role:Primary
replication:PausedSyncT peer-disk:UpToDate done:68.54
resync-suspended:dependency
[root@awsnode1 ~]# drbdadm status
lk0 role:Secondary
disk:UpToDate
awsnode11 role:Primary
peer-disk:UpToDate
awsnode2 role:Secondary
replication:SyncSource peer-disk:Inconsistent done:85.20- After synchronization is complete, switch over the service to the main site.
[root@awsnode1 ~]# lkcli resource restore --tag <service_tag>Failure notification
LifeKeeper’s event notification feature allows you to be notified when certain events occur. See LifeKeeper Event Forwarding via SNMP for details.
Tuning parameters
There are some tunable parameters for LifeKeeper and DRBD. You can use the default settings, but there are some cases where you may want to adjust them depending on your environment. This section describes some of these parameters.
Heartbeat, Confirm failover
- Heartbeat
There is no need to change the values unless there are regular downtime periods of 15 seconds or more between the main site and the backup site, try increasing the values of LCMHBEATTIME (default value 5) and LCMNUMHBEATS (default value 3) to see if there are any improvements.
- Confirm failover
The confirmso!<node> flag is set per node, and a confirmation message is displayed upon node failover from <node>. To prevent an unexpected failover to the backup site other than when the main site is down, set this option if you want the node to failover to the backup site after confirmation (it does not affect resource failover).
See WAN Configuration for more information.
DRBD Parameters
Some DRBD parameters are configured for the DRBD resource.
Dynamic resync speed (c-fill-target, c-min-rate, c-max-rate)
These parameters are used to tune DRBD’s variable synchronization rate, which tries to maximize network and disk bandwidth below c-max-rate, and slows down the synchronization rate if:
- there are more synchronization requests than the c-fill-target amount
- application I/O (write or read) is detected and the estimated sync rate exceeds c-min-rate
The c-fill-target parameter defines how much resynchronization data should always be retained while DRBD is running. In general, a good starting value for c-fill-target is two times the BDP (Bandwidth Delay Product).
https://linbit.com/drbd-user-guide/drbd-guide-9_0-en/#s-configure-sync-rate-variable
BDP is the product of bandwidth and round-trip time (RTT) and is equal to the maximum amount of data on the network at a given time, i.e., the amount of data that has been sent but not received an acknowledgment. Increasing this value means more data has been sent but has not yet received a response. Decrease the amount of data sent so that the data being sent does not exceed the c-fill-target.
These values are set when the DRBD resource is created, with c-fill-target 1MB (2048 sectors, 1 sector=512 bytes), c-min-rate 20MB/s, and c-max-rate 500MB/s. For example, assuming that between AWS Tokyo and Osaka regions, ping shows that the average RTT is 1.8 ms and iperf3 shows that the bandwidth is 4.5 Gbits/s = 562 MBytes/s, the BDP would be as follows:
BDP = 562 MBytes/s * 0.0018 s = 1.0 MBytes
A good starting value for c-fill-target is BDP * 2, which means it could be set around 2MB.
These parameters cannot be set from the GUI; they must be set via lkcli drbd options. Directly editing the /etc/drbd.d/lk*.res file is not supported.
# lkcli drbd options --tag drbd-disk1 --entry c-fill-target --value 2M --host1 awsnode1 --host2 awsnode11 --sys awsnode1
# lkcli drbd options --tag drbd-disk1 --entry c-fill-target --value 2M --host1 awsnode2 --host2 awsnode11 --sys awsnode2Fixed resync speed (c-plan-ahead, resync-rate)
c-plan-ahead defines how quickly DRBD adapts to changes in resync rate; when a DRBD resource is created, it is not configured and the default (20, 2 seconds in 0.1 increments) is used. It is recommended to set it to at least 5 times the RTT. If it is set to 0, dynamic resync speed is disabled and the value set by resync-rate is used as a fixed value (166 MB/s is set when the DRBD resource is created).
# lkcli drbd options --tag drbd-disk1 --entry c-plan-ahead --value 0 --host1 awsnode1 --host2 awsnode11 --sys awsnode1
# lkcli drbd options --tag drbd-disk1 --entry c-plan-ahead --value 0 --host1 awsnode2 --host2 awsnode11 --sys awsnode2Send buffer size (sndbuf-size)
sndbuf-size specifies the TCP send buffer size. It is not set when the DRBD resource is created; the default value (0: auto-tuning) is used. It can be set to a maximum of 10 MB. If there is a large latency due to the distance between regions, you may want to set a larger value from the beginning.
# lkcli drbd options --tag drbd-disk1 --entry sndbuf-size --value 10M --host1 awsnode1 --host2 awsnode11 --sys awsnode1
# lkcli drbd options --tag drbd-disk1 --entry sndbuf-size --value 10M --host1 awsnode2 --host2 awsnode11 --sys awsnode2AHEAD/BEHIND Mode (on-congestion, congestion-fill)
By default, write is blocked when the TCP send buffer is full. Although the buffer rarely becomes full with normal use, frequent large writes can block writes and affect application performance. If this happens frequently, you can set the policy to pull-ahead in the on-congestion option to switch to AHEAD/BEHIND mode before the send buffer becomes full, which allows only writing in the bitmap without performing replication. When sufficient buffers become available again, the node resumes synchronization with the peer node and returns to normal replication. This has the advantage of not blocking application I/O when buffers are full, but it also has the disadvantage of significantly delaying synchronization of the peer node. Note that while resynchronizing, the peer node is in an Inconsistent state and failover cannot be performed. The threshold for switching modes is specified by congestion-fill (default value is 0, which disables this congestion control mechanism) and should be smaller than sndbuf-size.
# lkcli drbd options --tag drbd-disk1 --entry on-congestion --value pull-ahead -c --host1 awsnode1 --host2 awsnode11 --sys awsnode1
# lkcli drbd options --tag drbd-disk1 --entry on-congestion --value pull-ahead -c --host1 awsnode2 --host2 awsnode11 --sys awsnode2
# lkcli drbd options --tag drbd-disk1 --entry congestion-fill --value 9M --host1 awsnode1 --host2 awsnode11 --sys awsnode1
# lkcli drbd options --tag drbd-disk1 --entry congestion-fill --value 9M --host1 awsnode2 --host2 awsnode11 --sys awsnode2See https://linbit.com/man/v9/?linbitman=drbdsetup.8.htm for details.
Post your comment on this topic.