
LifeKeeper は、LifeKeeper が保護するリソースのステータスと健全性をチェックするリアルタイムデーモンモニター lkcheck を装備しています。 In Service の各リソースについて、 lkcheck が定期的にそのリソースタイプの quickCheck スクリプトを呼び出します。 quickCheck スクリプトがリソースのクイック健全性チェックを実行し、リソースが障害のある状態にあると判断すると、 quickCheck スクリプトはイベント通知メカニズム sendevent を呼び出します。
以下の図に、 lkcheck がプロセスを開始したときのリカバリープロセスの作業を示します。
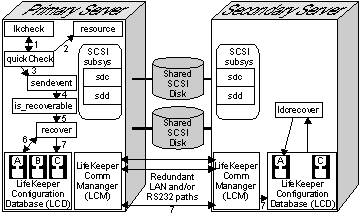
- lkcheck が実行されます。デフォルトでは、 lkcheck プロセスは 2 分ごとに実行されます。 lkcheck が動作すると、システムで In Service の各リソースについて適切は quickCheck スクリプトを呼び出します。
- quickCheck スクリプトがリソースをチェックします。 quickCheck スクリプトが実行するチェックの内容は、各リソースタイプによって異なります。通常、スクリプトは、リソースのクライアントの動作をシミュレートして、予測した応答を受信するかどうかを確認することにより、目的の作業を実行するためにリソースが使用可能かどうかを単純に確認します。
- quickCheck スクリプトが sendevent を呼び出します。 quickCheck スクリプトが、リソースが障害のある状態にあると判断した場合、 sendevent を呼び出して、適切なクラスとタイプを持つイベントを開始します。
- リカバリー手順の検索。システムイベント通知メカニズム sendevent は、はじめに、イベントタイプまたはコンポーネントについて、LCD がリソースまたはリカバリーを持つかどうかを判断しようとします。この判断を行うために、is_recoverable プロセスは LCD のリソース階層をスキャンして、イベントに対応するリソースインスタンス (この例では filesys の名前) を検索します。
次の手順の動作は、スキャンでリソースレベルのリカバリー手順が検出されたかどうかによって異なります。
• 検出されない場合:リカバリー手順が見つからない場合、is_recoverable は sendevent に戻り、 sendevent は基本イベント通知を続行します。
• 検出された場合:スキャンでリソースが検出された場合、is_recoverable はリカバリープロセスをバックグラウンドに運びます。is_recoverable プロセスが戻り、 sendevent が基本イベント通知を続行します。推奨フラグ「 -A 」を基本警告イベント応答スクリプトに渡し、LifeKeeper がリカバリーを実行することを示します。
- リカバリープロセスが開始されます。リカバリーが続行していると仮定して、is_recoverable はリカバリープロセスを開始し、はじめにローカルリカバリーを試行します。
- ローカルリカバリーが試行されます。インスタンスが検出された場合、リカバリープロセスは、LCD内のリソース階層にアクセスし、階層ツリーからイベントに応答する方法を知っているリソースを検索して、ローカルリカバリーを試行します。各リソースタイプについて、イベントクラスにちなむ名前を持つサブディレクトリ (そのイベントタイプのリカバリースクリプトを持つ) を含むリカバリーサブディレクトリを検索します。
リカバリープロセスが、リソース階層で障害が発生しているリソースから上方向に最も離れたリソースに関連付けられている、リカバリースクリプトを実行します。リカバリースクリプトが正常に完了した場合、リカバリーは停止します。スクリプトが失敗した場合、次のリソースに関連付けられたスクリプトが実行され、リカバリースクリプトが正常に完了するか、障害が発生したインスタンスに関連付けられたリカバリースクリプトが試行されるまで続行されます。
ローカルリカバリーが正常に完了した場合、リカバリーは停止します。
- サーバー間のリカバリーが開始されます。ローカルリカバリーに失敗した場合、イベントはサーバー間のリカバリーにエスカレートします。
- リカバリーが続行されます。ローカルリカバリーに失敗しているので、リカバリープロセスは失敗したインスタンスを Out-of-Service-FAILED (OSF) 状態にマークし、この失敗したリソースに依存するすべてのリソースを Out-of-Service-UNIMPAIRED (OSU) 状態にマークします。リカバリープロセスは次に、障害が発生したリソース、または障害が発生したリソースに依存するリソースが、他のシステム上にあるリソースとイクイバレンシー情報を持っているかどうかを判断し、優先順位が最高の動作可能なサーバーを選択します。同時にアクティブにできるイクイバレンシー情報を持つリソースは 1つのみです。
イクイバレンシー情報が存在しない場合、リカバリープロセスは停止します。
イクイバレンシー情報が検出されて選択された場合、LifeKeeper はサーバー間のリカバリーを開始します。リカバリープロセスが LCM 経由で、イクイバレンシー情報を持つリソースを持つ選択されたバックアップシステムの LCD プロセスにメッセージを送信します。これは、LifeKeeper がサーバー間のリカバリーを試行することを意味します。
複数の共有イクイバレンシーがある場合、 lcdrecover プロセスは、LifeKeeperが階層内のすべてのリソースがフェイルオーバーできることを確認できる、最も優先度の高いサーバーを選択します (各リソースには、リストアの完了を妨げるものがないことを確認するcanfailoverユーティリティがあります)。LifeKeeperは、階層を最も優先度の高いサーバーにフェイルオーバーできないと判断した場合、すべてのサーバーがチェックされるまで、次に優先度の高いサーバーをチェックします。LifeKeeperがすべてのサーバーの階層を稼働中にできないと判断した場合、リソースの移動は行われません。
- lcdrecover プロセスが転送を調整します。バックアップサーバーの LCD プロセスが lcdrecover プロセスを運び、同等リソースの転送を調整します。
- バックアップサーバーのアクティブ化。 lcdrecover プロセスが同等のリソースを検出し、そのリソースが Out of Service のリソースに依存しているかどうかを判断します。 lcdrecover が、必要な各リソースについて restore スクリプト (リソースリカバリー動作スクリプトの一部) を実行し、リソースを in-service にします。
バックアップサーバーでリソースをリストアすることにより、プライマリーシステムからより多くの共有リソースを転送することが必要になる場合があります。プライマリーシステムとの間で、プライマリーサーバー上でのサービスから削除する必要があるリソースを示すメッセージが送受信され、次に選択したバックアップサーバーで in-service になり、重要なアプリケーションのすべての機能が提供されます。この動作は、転送する追加の共有リソースがなくなり、バックアップで必要なすべてのリソースインスタンスがリストアされるまで続行されます。
このトピックへフィードバック