
The LifeKeeper Generic Application Recovery Kit for Load Balancer Health Checks (“GenLB Recovery Kit”) may be used as part of a LifeKeeper resource hierarchy to help route load balancer traffic to the cluster node where a particular resource is currently in-service. This is achieved by maintaining a listener on a user-specified TCP port on the cluster node where the resource is in-service.
Install the GenLB Recovery Kit
The GenLB Recovery Kit is only supported on SIOS Protection Suite for Linux version 9.5.1 and later, and an rpm installation file can be obtained from the same FTP directory where the SIOS Protection Suite for Linux installation media was downloaded. The filename format is steeleye-lkHOTFIX-Gen-LB-PL-7172-x.x.x-xxxx.x86_64.rpm. No additional SIOS licenses are required in order to create GenLB resources.
- Install the rpm:
[root@node-a ~]# rpm -ivh steeleye-lkHOTFIX-Gen-LB-PL-7172-x.x.x-xxxx.x86_64.rpm Verifying... ####################### [100%] Preparing... ####################### [100%] Updating / installing... 1:steeleye-lkHOTFIX-Gen-LB-PL-7172-# [100%]
- Verify that the GenLB resource action scripts have been successfully installed to the /opt/LifeKeeper/SIOS_Hotfixes/Gen-LB-PL-7172 directory.
[root@node-a ~]# ls -l /opt/LifeKeeper/SIOS_Hotfixes/Gen-LB-PL-7172/ total 12 -r-x------ 1 root root 2579 Jan 01 00:00 quickCheck -r-x------ 1 root root 1734 Jan 01 00:00 remove.pl -r-x------ 1 root root 3909 Jan 01 00:00 restore.pl
Create Frontend IP Resource(s)
When using a Google Cloud load balancer with IP forwarding disabled (see the ‘Disable IP Forwarding’ section of Google Cloud – Using an Internal Load Balancer), the IP address(es) associated to the load balancer frontend(s) must be added to a local network interface on each backend server using network mask /32 (equivalently, 255.255.255.255). In these configurations, the load balancer frontend IP address is not automatically added to a network interface by any cloud agent process. Instead, it must be added manually within the guest operating system on each backend server. The simplest way to achieve this is by creating a LifeKeeper IP resource for each load balancer frontend IP address, which will then be added as a dependency of the GenLB resource that will be created in the next section.
Following the steps given in Creating an IP Resource, create and extend an IP resource for each load balancer frontend IP address using the following parameters:
| Create Resource Wizard | |
|---|---|
| Switchback Type | intelligent |
| Server | node-a |
| IP Resource | <Frontend IP Address> |
| Netmask | 255.255.255.255 |
| Network Interface | <Network Interface> |
| IP Resource Tag | <Resource Tag> |
| Pre-Extend Wizard | |
| Target Server | node-b |
| Switchback Type | intelligent |
| Template Priority | 1 |
| Target Priority | 10 |
| Extend comm/ip Resource Hierarchy Wizard | |
| IP Resource | <Frontend IP Address> |
| Netmask | 255.255.255.255 |
| Network Interface | <Network Interface> |
| IP Resource Tag | <Resource Tag> |
Now that IP resources have been created for each load balancer frontend IP address, we may now create the GenLB resources that will respond to the load balancer health check probes.
Create a GenLB Resource
In this example we will create a sample GenLB resource on server node-a listening on TCP port 54321.
- In the LifeKeeper GUI, click
![]() to open the Create Resource Wizard. Select the “Generic Application” Recovery Kit.
to open the Create Resource Wizard. Select the “Generic Application” Recovery Kit.
 to open the Create Resource Wizard. Select the “Generic Application” Recovery Kit.
to open the Create Resource Wizard. Select the “Generic Application” Recovery Kit.
- Enter the following values into the Create Resource Wizard and click Create when prompted. The
![]() icon indicates that the default option is chosen. The “Application Info” field has the format “<TCP Port> <Response>”. The response is optional, and no whitespace is allowed in the response text.
icon indicates that the default option is chosen. The “Application Info” field has the format “<TCP Port> <Response>”. The response is optional, and no whitespace is allowed in the response text.
 icon indicates that the default option is chosen. The “Application Info” field has the format “<TCP Port> <Response>”. The response is optional, and no whitespace is allowed in the response text.
icon indicates that the default option is chosen. The “Application Info” field has the format “<TCP Port> <Response>”. The response is optional, and no whitespace is allowed in the response text.| Switchback Type | Intelligent |
| Server | node-a |
| Restore Script | /opt/LifeKeeper/SIOS_Hotfixes/Gen-LB-PL-7172/restore.pl |
| Remove Script | /opt/LifeKeeper/SIOS_Hotfixes/Gen-LB-PL-7172/remove.pl |
| QuickCheck Script | /opt/LifeKeeper/SIOS_Hotfixes/Gen-LB-PL-7172/quickCheck (Note: Although the quickCheck script may be optional for some ‘Generic Application’ resource types, it is required for GenLB resources.) |
| Local Recovery Script | None (Empty) |
| Application Info | 54321 |
| Bring Resource In Service | Yes |
| Resource Tag | ilb-test-54321 |
Once the resource has been created and brought in-service successfully, click Next> to proceed to the Pre-Extend Wizard.

- Enter the following values into the Pre-Extend Wizard. The
![]() icon indicates that the default option is chosen.
icon indicates that the default option is chosen.
| Target Server | node-b |
| Switchback Type | Intelligent |
| Template Priority | 1 |
| Target Priority | 10 |
Once the pre-extend checks have passed, click Next> to proceed to the Extend gen/app Resource Hierarchy Wizard.

- Enter the following values into the Extend gen/app Resource Hierarchy Wizard and click Extend when prompted. The
![]() icon indicates that the default option is chosen.
icon indicates that the default option is chosen.
| Resource Tag | ilb-test-54321 |
| Application Info | 54321 |
Once the resource has been extended successfully, click Finish.

- Back in the LifeKeeper GUI, we see that the newly created ilb-test-54321 resource is Active on node-a and Standby on node-b. In this state, a TCP load balancer with a TCP health check on port 54321 will treat node-a as healthy and node-b as unhealthy, causing all load balancer traffic to be routed to node-a. When placed in a resource hierarchy with a protected application, this resource will ensure that load balancer traffic is always routed to the server on which the application is currently running.

Add Frontend IP Resources as Dependencies of GenLB Resource
When using a Google Cloud load balancer with IP forwarding disabled (see the ‘Disable IP Forwarding’ section of Google Cloud – Using an Internal Load Balancer), IP resource(s) protecting the IP address(es) associated to the load balancer frontend(s) (using network mask 255.255.255.255) must be added as dependencies of the GenLB resource. Complete the following steps for each of the IP resources created in the ‘Create Frontend IP Resource(s)’ section above.
- Right-click on the ilb-test-54321 resource and select Create Dependency… from the drop-down menu.
- For Child Resource Tag, specify the resource protecting the frontend IP address of the load balancer.
- Click Next> to continue, then click Create Dependency to create the dependency.
Once the IP resource has been added as a dependency, the resulting hierarchy will look similar to the following:
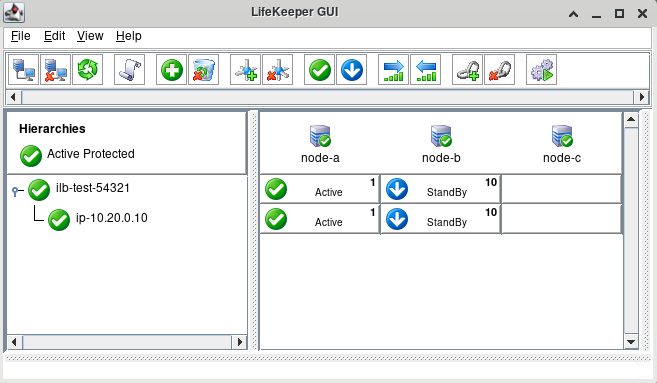
Test GenLB Resource Switchover and Failover
In this section we will assume that we have created an internal load balancer with node-a and node-b as backend targets which has the following properties:
- Front-end internal IP: 10.20.0.10
- TCP health check on port 54321
and that the ilb-test-54321 GenLB resource that was created in the previous section is currently Active on node-a.
For convenience we will set up a temporary Apache web server that will simply return the hostname of each server. Execute the following commands on both node-a and node-b. Adjust the commands accordingly (e.g., to use zypper install) if installing on a SLES server.
# yum install -y httpd # systemctl start httpd # echo $(hostname) > /var/www/html/index.html
Before continuing, verify that traffic is allowed on TCP port 80 for node-a and node-b.
We will now test the switchover and failover capabilities of the ilb-test-54321 GenLB resource.
- With the ilb-test-54321 resource Active on node-a and Standby on node-b, verify the output of the following command on each server.
[root@node-a ~]# curl http://10.20.0.10 node-a [root@node-b ~]# curl http://10.20.0.10 node-a
- Execute the following command on node-a:
[root@node-a ~]# while true; do curl http://10.20.0.10; sleep 1; done
and initiate a switchover of the ilb-test-54321 resource to node-b. Once the switchover has completed successfully, use Ctrl-C (SIGINT) to terminate the running command on node-a.
The output of the command should be similar to:
…
node-a
node-a
node-a
[switchover occurs]
node-b
node-b
node-b
…
In particular, the load balancer should cleanly stop routing traffic to node-a before beginning to route it to node-b. If the output near the switchover point looks like the following:
…
node-a
[switchover occurs]
node-b
node-a
node-b
node-a
node-b
node-a
node-b
node-b
node-b
…
then you may need to edit the health check properties to decrease the time between health check probes and/or decrease the minimum number of unsuccessful health check probes before a backend instance is marked unhealthy and removed from the load balancer pool. See the Tuning Load Balancer Health Check Parameters section below for more details.
- With the ilb-test-54321 resource Active on node-b, execute the following command on node-a:
[root@node-a ~]# while true; do curl http://10.20.0.10; sleep 1; done
and forcefully reboot node-b to initiate a failover of the ilb-test-54321 resource back to node-a:
[root@node-b ~]# echo b > /proc/sysrq-trigger
After the failover has completed successfully, use Ctrl-C (SIGINT) to terminate the running command on node-a.
The output of the command on node-a should be similar to:
…
node-b
node-b
node-b
[failover occurs]
node-a
node-a
node-a
…
At this point basic verification of the GenLB resource behavior is complete. Execute additional tests as necessary to verify the interaction between the GenLB resource and your protected application on switchover and failover. Once finished testing the GenLB resource functionality, the temporary Apache web servers may be removed by executing the following commands on both node-a and node-b:
# systemctl stop httpd # rm -f /var/www/html/index.html # yum remove -y httpd
Tuning Load Balancer Health Check Parameters
While the default load balancer health check parameters should work in most common situations, it may be necessary to tune them in order to achieve the desired switchover behavior. There are two typical issues that might require a user to tune these parameters:
- The values are set too low, causing the load balancer to be too sensitive to temporary resource constraints or network interruptions.
- The values are set too high, causing the previous resource host to still be marked as healthy as the load balancer begins routing traffic to the new resource host during a switchover.
There are typically four primary health check parameters that may be tuned in a cloud load balancing environment:
- Health Check Interval – How often the health check servers send health check probes to the backend target VMs.
- Timeout – How long a health check server will wait to receive a response before considering the health probe failed.
- Healthy Threshold – The number of consecutive health check probes that must receive successful responses in order for a backend target VM to be marked as healthy.
- Unhealthy Threshold – The number of consecutive health check probes that must fail in order for a backend target VM to be marked as unhealthy.
See Microsoft Azure – Load Balancer Health Probes and Google Cloud – Health Checks Overview for more details about these parameters.
From these parameters, we can also derive the following values:
- Total Time to Mark Healthy = Health Check Interval × (Healthy Threshold – 1) – The total amount of time after the initial health check probe of a healthy server before it is marked healthy by the load balancer, assuming low network latency between the server and the health probe servers.
- Total Time to Mark Unhealthy = Timeout × Unhealthy Threshold – The total amount of time after the initial health check probe of a failed server before it is marked unhealthy by the load balancer.
While the exact values for these parameters will vary depending on each user’s particular environment, some general guidelines are given below.
- Tuning either the Timeout or Unhealthy Threshold too low may result in a load balancer configuration which is not resilient against temporary VM resource constraints or transient network issues. For example, setting extreme values such as Timeout = 1 second and Unhealthy Threshold = 1 failure would cause a backend VM to be marked unhealthy even if the network became unresponsive for only a few seconds, which is not uncommon in cloud environments. It is recommended to leave the Timeout at a reasonable value (e.g., 5 seconds) to allow the load balancer configuration to be more resilient against minor transient issues.
- If the combination of Health Check Interval and Healthy Threshold is set too high, the load balancer may take an unnecessarily long time to begin routing traffic to the new resource host after a switchover or failover, prolonging the recovery time for the application. Setting the value Healthy Threshold = 2 consecutive successes should be appropriate for most situations.
- If the combination of Timeout and Unhealthy Threshold is set too high, the load balancer will not react quickly enough to mark the previous resource host node as unhealthy after a switchover, and there may be a period where load balancer traffic is being routed to both the active and standby servers in a round-robin format. In order to avoid this situation, it is recommended to gather data from several switchovers of the resource hierarchy to determine the minimum time between the GenLB resource being taken out-of-service on the previous host and being brought in-service on the new host. Assuming that the time is synchronized between the cluster servers, this can be found by inspecting /var/log/lifekeeper.log on each server and determining the amount of time between the end of the GenLB remove script on the previous host and the end of the GenLB restore script on the new host. We will denote this amount of time (in seconds) as Minimum GenLB Switchover Time. The recommendation then is to set the load balancer health check parameters such that:
Total Time to Mark Unhealthy < Minimum GenLB Switchover Time + Total Time to Mark Healthy
In the common situation where the Timeout value is chosen to be the same as the Health Check Interval (e.g., both are set to 5 seconds), this recommendation is equivalent to:
Unhealthy Threshold < (Minimum GenLB Switchover Time / Timeout) + Healthy Threshold – 1
As an example, suppose that we have configured our load balancer health check parameters with Health Check Interval = Timeout = 5 seconds and Healthy Threshold = 2 consecutive successes. By gathering data from repeated switchover tests with our resource hierarchy, we find empirically that Minimum GenLB Switchover Time = 20 seconds. Using the recommendation given above, we should choose Unhealthy Threshold so that:
Unhealthy Threshold < (20 / 5) + 2 – 1 = 5
Based on this, any value from 2 to 4 consecutive failures could be a reasonable choice for Unhealthy Threshold. If we find during switchover testing that the load balancer is not marking the previous host as unhealthy quickly enough after switchover then we would select a lower value (e.g., 2 or 3). If we find during testing that the load balancer regularly marks the current resource host as unhealthy due to transient server or network issues, then we would select a higher value (e.g., 3 or 4). Choosing Unhealthy Threshold = 3 consecutive failures could be a reasonable compromise in this example.
このトピックへフィードバック