
クラスター内のすべてのノードからアクセスできる共有ストレージを用いた合意システムで、共有ストレージを介してノードの情報交換を行います。各ノードは自ノード情報を定期的に共有ストレージに書き込み、また定期的に他ノードが書き込んだノード情報を読み込みます。(共有ストレージに書き込まれたノード情報を QWK オブジェクト または QWK と呼びます。QWK オブジェクトはクラスターを構成する全ノードの分だけ必要です)。クラスター内ノードの過半数が共有ストレージにアクセスでき、他ノードのQWK オブジェクトがアップデートされているのを確認できる状態のときに、クラスターは Quorum合意を持つとします。
Quorumチェックでは、共有ストレージにアクセスできることで Quorumチェック成功と判断します。また、Witnessチェックでは、他ノードの QWK オブジェクトにアクセスし、QWKオブジェクトの定期更新が行われているかチェックします。一定期間QWKオブジェクトの更新が止まっていれば、対応するノードの障害が発生していると判断します。なお、Witnessチェック中も自ノードのQWKオブジェクトの更新は行われています。また、実装上は、Quorumチェック時にWitnessチェックも実施しています。
Quorumモードに “Storage” を選んだ場合、後述のWitness モードも “Storage” を選択しなければなりません。
この Quorum設定は、ノードの数が偶数のクラスターで推奨されます。別途、クラスターを構成するノード数分のQWKオブジェクトを格納するための共有ストレージが必要です。なお共有ストレージにアクセスできなくなると、リソースの起動状態に影響します。すべてのノードから常時アクセス可能な共有ストレージを選定してください。
利用可能な共有ストレージ
Quorum/Witness機能の目的であるスプリットブレイン回避を確実なものにするために、Quorumの分離が発生しない構成(例:ノードAのQWKオブジェクトにアクセス可能であるが、ノード BのQWK オブジェクトにアクセス不能)としなければなりません。そのためには、すべてのQWKオブジェクトを同じ共有ストレージの場所(同じSMB共有または同じS3バケット)に配置する必要があります。
利用可能な共有ストレージは以下の通りです。 %LKROOT%/etc/default/LifeKeeper 設定ファイルのQWK_STORAGE_TYPEで指定します。
| file (SMB をサポート) |
共有ストレージにSMBを使う場合、1つのQWKオブジェクトは以下に配置してください。 1 QWK オブジェクト = SMB ファイル共有内の 1 ファイル Azure Files のSMBプロトコル経由での使用もサポートされますが、以下の点を考慮する必要があります。
|
| aws_s3 | 共有ストレージに Amazon Simple Storage Service (S3) を使う場合、1つのQWK オブジェクトは以下に配置してください。 1 QWK オブジェクト = 1 S3 オブジェクト LifeKeeper が動作しているインスタンスのリージョンと別のリージョンの S3 を利用してください。これは、同一リージョンの S3 を利用した場合に AZ(Availability Zone) 間の接続が分断されると、複数 AZ にレプリケーションが配置されている S3 も同時に分断し、S3 への一貫性のあるアクセスが期待できないためです。
インターネットに接続できない環境から別リージョンのAmazon S3にアクセスする場合、またはAmazon S3互換のオブジェクトストレージにアクセスする場合はエンドポイントおよびリージョンの指定が必要です。リージョンを指定すると、上記のs3:GetBucketLocation権限は不要です。詳細は「Quorum パラメーター一覧 」のQWK_STORAGE_OBJECT_<ホスト名>を参照してください。 Amazon S3互換のオブジェクトストレージを使う場合は「利用可能なAmazon S3互換のオブジェクトストレージ 」をご覧ください。
|
1 QWK オブジェクトのサイズは4096バイトです。
自ノード QWK オブジェクトに対しては read / write を行います。他ノードの QWK オブジェクトに対しては read のみ行います。アクセス権限を適切に設定し、すべてのノードがすべてのオブジェクトへの読み取りアクセス権を持ち、自分のオブジェクトへの書き込みアクセス権を持つようにします。
Storage モードの設定
%LKROOT%/etc/default/LifeKeeper 設定ファイルで QUORUM_MODE と WITNESS_MODE の設定を「storage」に設定してください。また、他に以下の設定があります。- QWK_STORAGE_TYPE – 使用する共有ストレージの種類を指定します。
[必須]
- QWK_STORAGE_HBEATTIME – QWKオブジェクトの読み書きの間隔を秒単位で指定します。この設定は、LCMHBEATTIME のデフォルト設定以上でなければなりません。
[必須]
- QWK_STORAGE_NUMHBEATS – ハートビートチェックの連続回数を指定します。ハートビートチェックに失敗した場合は、ターゲットノードに障害が発生したことを示します。ハートビートチェックの失敗は、QWK オブジェクトが前回のチェック以降に更新されていない場合に発生します。この設定は、LCMNUMHBEATS のデフォルト設定値以上でなければなりません。
[必須]
注意: トラフィックが追加された時間とトラフィックのない時間の比較に基づいて、 上記の QWK_STORAGE_HBEATTIME と QWK_STORAGE_NUMHBEATS を調整できます。 デフォルトでは、QWK_STORAGE_HBEATTIME は6秒(最小5秒、最大10秒)、QWK_STORAGE_NUMHBEATSは4秒(最小3秒)です。
- QWK_STORAGE_OBJECT_ – クラスター内の各ノードのQWKオブジェクトのパスを指定します。クラスター内のすべてのノードのパスを指定する必要があります。
[必須]
- HTTP_PROXY、HTTPS_PROXY、NO_PROXY – AWS サービスエンドポイントへのアクセスでHTTPプロキシを使用する場合に設定してください。ここで設定した値がそのまま AWS CLI へ渡されます。[オプション]
詳細は 「Quorumパラメーター一覧 」を参照してください。
Storage モードの使用手順
本モードで使用する場合は、初期化が必要です。以下の手順に従って初期化してください。
- クラスターを構成するすべてのサーバーをセットアップして、他のサーバーとネットワーク通信ができることを確認します。
- すべてのノード間にコミュニケーションパスを作成します。
- すべてのノードで %LKROOT%/etc/default/LifeKeeper 設定ファイルの設定を行います。
- すべてのノードで qwk_storage_init コマンドを実行します。このコマンドは、すべてのノードで QWK オブジェクトの初期化が終わるまで待ち状態になります。このコマンドがすべてのノードで終了すると、storage モードとして Quorum/Witness 機能が利用できる状態となります。
初期化後にクラスターを構成するノードの追加・削除をする、または %LKROOT%/etc/default/LifeKeeper 設定ファイルのパラメーターを変更する場合、再初期化が必要です。以下の手順に従って再初期化してください。
- すべてのノードで qwk_storage_exit コマンドを実行します。
- ノードを削除する場合、削除するノードと他すべてのノード間のコミュニケーションパスを削除します。ノードを追加する場合、追加するノードと他すべてのノード間にコミュニケーションパスを作成します。
- すべてのノードで %LKROOT%/etc/default/LifeKeeper 設定ファイルを再設定します。
- すべてのノードで qwk_storage_init コマンドを実行します。
Storage モードの期待される動作(デフォルト設定を仮定)
ノード A(リソースは稼働状態)、ノード B(リソースは待機状態)の2ノード構成のクラスターの動作について示します。
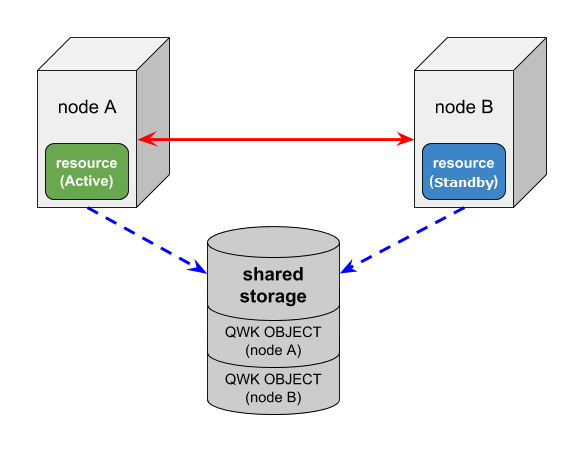
なお、ノード障害に関するリソースの状態を変更し得るイベントは以下の3つです。
- COMM_DOWN イベント
ノード間のコミュニケーションパスが全て切断した時に呼び出されるイベント。
- COMM_UP イベント
COMM_DOWN 状態からコミュニケーションパスが復旧した際に呼び出されるイベント。
- LCM_AVAIL イベント
LCM の初期化が終わった時に呼び出されるイベントで、LifeKeeper 起動時に1度だけ呼び出される。一度 LCM_AVAIL になると、接続が確立されたコミュニケーションパス上でクラスター内の他ノードへのハートビートの送信が開始される。また、他ノードからのハートビート要求の受信も受けられるようになる。LCM_AVAIL イベントの処理は必ず COMM_UP イベントの処理より前に行われる。
シナリオ 1
ノード A とノード B の間のコミュニケーションパス通信に障害が発生(ノード A とノード B とも共有ストレージにアクセス可能)
この場合、以下のように動作します。
- ノード A とノード B は、COMM_DOWN イベントの処理を開始します。ただし、全く同時とは限りません。
- 両方のノードは Quorum チェックを実行し、両方共自身が Quorum を持っていると判断します(共有ストレージアクセスが可能であるため)
- 各ノードは、通信できなくなったノードの QWK オブジェクトの更新を確認します(Witness チェック)。ノード A とノード B は共に稼働しているため、両ノードは定期的に QWK オブジェクトが更新されていることを確認します。
- Witness チェックの結果、他方のノードがまだ生存しているためフェイルオーバー処理は発生しません。リソースはノード A で稼働状態のままになります。
シナリオ 2
ノード A に障害が発生してノード A が停止
この場合、ノード B は以下の動作をします。
- ノード A との COMM_DOWN イベントの処理を開始します。
- 共有ストレージにアクセス可能であるので、Quorum を持っていると判断します。
- ノード A の QWK オブジェクトの更新が停止していることを確認します(Witness チェック)。
- Witness チェックの結果、ノード A で障害が発生していると判断したため通常のフェイルオーバー処理を開始します。これにより保護対象のリソースはノード B で稼働中になります。
リソースがノード B で稼働中に、通信可能かつ共有ストレージにアクセス可能な状態でノード A のサーバーが電源ON
この場合、ノード A は LCM_AVAIL イベントを処理します。ノード A は、Quorum を持っていると判断し、ノード B でリソースが稼働中のためリソースを起動させません。また、その直後に、COMM_UP イベントが各ノードで発生します。
各ノードの COMM_UP イベントの処理では、Quorum を持っていると判断し、またノード B でリソースが稼働中のためリソースは起動させません。
リソースがノード B で稼働中に、通信不能かつ共有ストレージにアクセス可能な状態でノード A のサーバーが電源ON
この場合、ノード A は LCM_AVAIL イベントを処理します。ノード A は、Quorum を持っていると判断し、通信できないノード B に障害が発生しているか確認するためノード B の QWK オブジェクトの更新を確認します。ノード B は稼働しているため、QWK オブジェクトは定期的に更新されます。ノード A では QWK オブジェクトの更新を確認し、ノード B が生存しているが通信できないためにリソースは起動させません。ノード B はノード A と通信できず、すでにリソースが稼働中なので何もしません。
シナリオ 3
ノード A のネットワークに障害が発生(ノード A は稼働しているが、他のノードや共有ストレージにアクセス不能)
この場合、ノード A は以下の動作をします
- ノード B との COMM_DOWN イベントの処理を開始します。
- 共有ストレージにアクセス不能であるため、Quorum を持っていないと判断します。
- QUORUM_LOSS_ACTIONで 指定している OSU 操作を実行します(階層をサービス停止にし、Quorum Quarantine 状態、すなわちQuorum 喪失後の待機状態にします。)
- QUORUM_QUARANTINE_SECS の後、LifeKeeper は再起動し、通信の確立を試みます。
また、ノード B は以下の動作をします。
- ノード A との COMM_DOWN イベントの処理を開始します。
- 共有ストレージにアクセス可能であるため、Quorum を持っていると判断します。
- ノード A の QWK オブジェクトの更新が停止していることを確認します(Witness チェック)。
- Witness チェックの結果、ノード A で障害が発生していると判断したため通常のフェイルオーバー処理を開始します。これにより保護対象のリソースはノード B で稼働中になります。
リソースがノード B で稼働中であり、QUORUM_QUARANTINE_SECS を待機した後、ノード A は QWK 共有ストレージにアクセスでき、ノード B と通信可能
この場合、ノード A は LCM_AVAILイベントを処理します。ノードAは、Quorumを持っていると判断しますが、現在ノードBで稼働中であるため、リソースを起動させません。その後、COMM_UPイベントが各ノードで発生します。
各ノードのCOMM_UPイベントの処理では、Quorumを持っていると判断し、またノードBでリソースが稼働中のためリソースは起動させません。
このトピックへフィードバック