
Microsoft SQL Server 2014 フェールオーバークラスターの Azure リソース マネージャー(ARM)へのデプロイ
始める前に DataKeeper Cluster Edition リリースノート を読んで最新情報を入手してください。DataKeeper Cluster Edition インストレーションガイド を読んで理解しておくことを強くお勧めします。
Azure リソース マネージャーを使用して2ノードの SQL Server フェールオーバークラスターを単一の領域にデプロイするために必要な手順
注記: 本ガイドは、Azure の Classic ポータルには適用されません。
DataKeeper Cluster Edition を使用すると、Premium ディスクまたは Standard ディスクのどちらを使用していても、ローカルに接続されたストレージを使用できます。また、複数のクラスターノード間でこれらのディスクを同期または非同期で、2種類の混在または両方で複製できます。また、DataKeeper ボリュームリソースが Windows Server フェールオーバークラスターに登録されており、これが物理ディスクリソースの代わりになります。物理ディスクリソースのような SCSI-3 予約を制御する代わりに、DataKeeper ボリュームはミラー方向を制御し、アクティブノードが常にミラーのソースであることを保証します。SQL Server およびフェールオーバークラスターの場合、DataKeeper ボリュームは物理ディスクのようであり、物理ディスクリソースと同じ方法で使用されます。
要件
- これまでに Azure Portal (http://portal.azure.com) を使用したことがあり、Azure IaaS 環境で仮想マシンをデプロイすることに慣れている。
- SIOS DataKeeper の 評価版ライセンス または製品ライセンスを取得している。
POC(Proof-Of-Concept)の簡単な方法
Azure リソースマネージャーは、デプロイ テンプレートを使用して相互に関連する Azure リソースで構成されるアプリケーションを迅速にデプロイする機能を備えています。これらのテンプレートの多くは Microsoft によって開発されたもので、クイックスタート テンプレートとして Github のコミュニティですぐに利用できます。 コミュニティのメンバーはテンプレートを拡張したり、独自のテンプレートを GitHub に公開したりすることもできます。サイオステクノロジーが発行した 『SQL Server 2014 AlwaysOn Failover Cluster Instance with SIOS DataKeeper Azure Deployment Template』 というタイトルのテンプレートは、2ノードの SQL Server FCI を新しい Active Directory ドメインに展開するプロセスを完全に自動化します。
このテンプレートをデプロイするには、テンプレート内の [Deploy to Azure] をクリックします。

2ノードの SQL クラスターを迅速にプロビジョニングするには、github.com/SIOSDataKeeper/SIOSDataKeeper-SQL-Cluster を参照してください。
Azure PORTAL を使用した SQL Server フェールオーバークラスター インスタンスのデプロイ
Azure の自動化されたデプロイ用テンプレートは、2ノードの SQL Server FCI を素早く起動するための迅速かつ簡単な方法ですが、いくつかの制限があります。1つは、このテンプレートは180日間の評価版の SQL Server を使用するため、SQL 評価版ライセンスをアップグレードしない限り、本番環境では使用できません。 また、完全に新しい AD ドメインを構築するので、既存のドメインと統合する場合は、手動で再構築する必要があります。
ドメイン コントローラー(DC1)のプロビジョニング
Azure で2ノードの SQL Server フェールオーバークラスター インスタンスを構築するには、Azure Resource Manager(Azure Classic ではありません)および最低でも1台の仮想マシンをドメイン コントローラーとして構成して実行する基本的な仮想ネットワークが必要です。本ガイドでは、この手順については説明しません。また本ガイドでは、ドメイン コントローラーを DC1と呼びます。DC1を作成する際に、Windows Server 2008 R2 または Windows Server 2012 R2 を選択できます。DC1は、クラスターノード、SQL1および SQL2と同じ種類(Premium または Standard)であり、同じ可用性セットにあることが要件です。仮想ネットワークとドメイン コントローラーを設定したら、クラスター内の2つのノードとして動作する2台の仮想マシンをプロビジョニングします。
例:
DC1 – ドメイン コントローラーおよびファイル共有監視
SQL1 および SQL2 – SQL Server クラスターの2つのノード
2つのクラスター ノードのプロビジョニング(SQL1 およびSQL2)
Azure Portal を使用して、SQL1 と SQL2 の両方を全く同じ方法でプロビジョニングします。インスタンスのサイズ、ストレージのオプションなど、さまざまなオプションを選択できます。このガイドは、Azure に SQL Server をデプロイするための包括的なガイドではありません。インスタンスを作成する際、特にクラスター環境では、注意すべき点がいくつかあります。
可用性セット – SQL1、SQL2 および DC1 は、同じ可用性セットにある必要があります。これらを同じ可用性セットに入れることによって、各クラスターノードとファイル共有監視が、異なる障害ドメインと更新ドメインに存在するようにします。これにより、計画されたメンテナンスと計画外メンテナンスのいずれにおいても、クラスターはクォーラムを維持してダウンタイムを回避できるようになります。
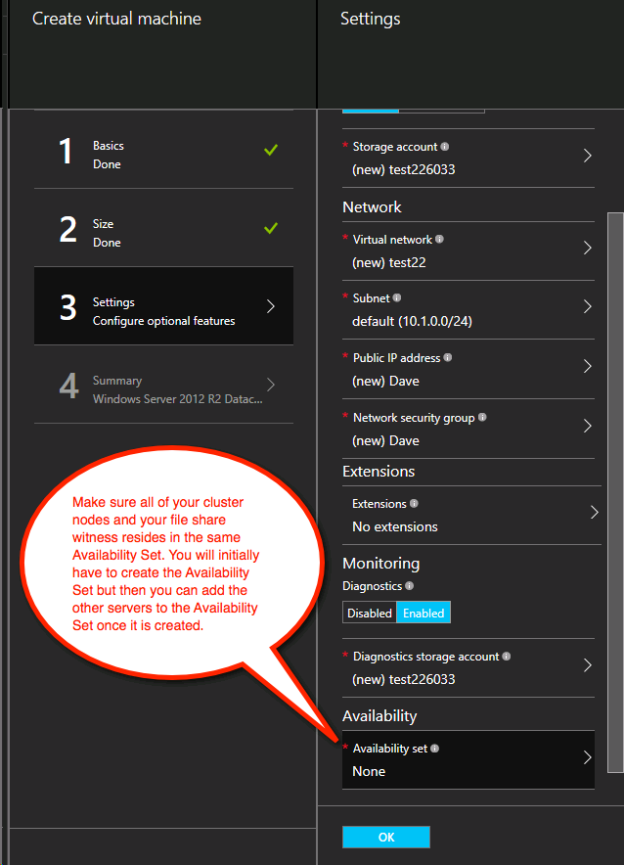
静的 IP アドレス
各 VM をプロビジョニングしたら IP アドレスの設定を [Static] に変更して、クラスターノードの IP アドレスが変更されないようにします。
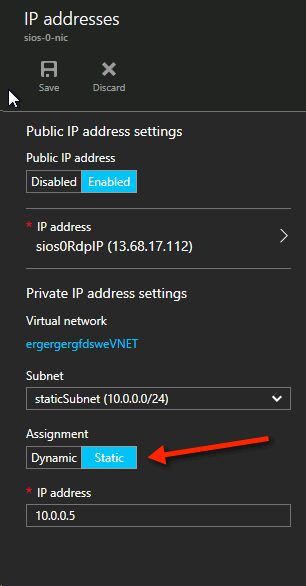
ストレージ
ストレージに関する情報は、Azure Virtual Machines における SQL Server のパフォーマンスに関するベスト プラクティス を参照してください。各クラスターノードに最低でも1つの追加ディスクを追加します。DataKeeper では Premium ディスクまたは Standard ディスクを使用できますが、Azure では OSディスクと同じタイプを使用するようにデータディスクを設定する必要があります。Premium ディスクにある VM を作成した場合は、Premium データディスクも接続する必要があります。DataKeeper はストレージプールと互換性があるため、選択した VM のサイズで許容される場合は、複数のデータディスクを接続できます。
クラスターの作成
上記のように両方のクラスターノード(SQL1とSQL2)をプロビジョニングし、既存のドメインに追加したら、クラスターを作成できます。クラスターを作成する前に、両方のクラスターノードで適切な .NET フレームワークおよびフェールオーバークラスタリング機能の両方を有効にする必要があります。
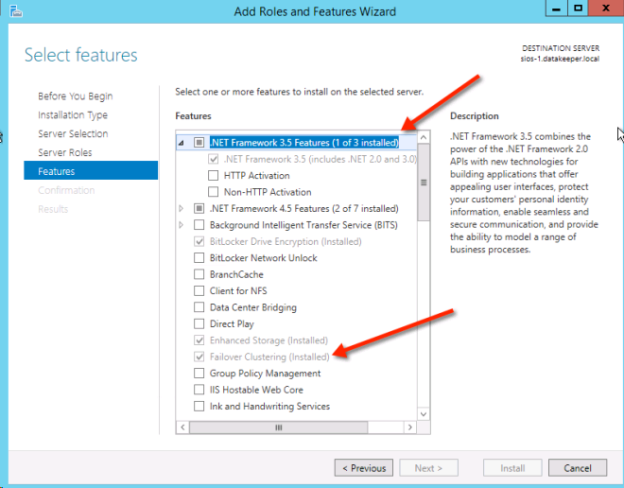
これらの機能が有効になれば、クラスターを構築することができます。次の手順は PowerShell とWSFC GUI の両方で実行できますが、PowerShell を使用してクラスターを作成することを推奨します。
注記: フェールオーバークラスター マネージャーの GUI を使用すると、接続されていないクラスターに重複した IP アドレスが発行されます。
Azure VM では、DHCP を使用する必要があります。VM作成時に Azure ポータルで「静的 IP」を指定することにより DHCP 予約と同様のものが確立されますが、実際の DHCP 予約が DHCP プールより IP アドレスを削除するため、これは厳密には DHCP 予約ではありません。その代わり、Azure ポータルで静的 IP を指定し、VM の要求時にその IP アドレスが使用可能な場合、Azure はその IPアドレス を発行します。ただし、VM がオフラインで、別のホストが同じサブネット内でオンラインになると、その同じ IP アドレスを発行できます。
Azure で DHCPを実装する方法には、もう1つの副作用があります。Windows Server フェールオーバークラスター GUI を使用してクラスターを作成する場合、ホストが DHCP を使用する(必須)際にクラスターの IP アドレスを指定するオプションはありません。代わりに DHCP を使用してアドレスを取得しますが、DHCP は重複した IP アドレスを発行します。これは通常、要求元のホストと同じ IP アドレスです。クラスターの作成は通常は問題なく完了しますが、エラーが発生する場合があります。その場合には、Windows Server フェールオーバークラスターの GUI を別のノードから起動する必要があります。起動したら、クラスターの IP アドレスを、ネットワーク上で現在使用されていないアドレスに変更します。
これを回避するには、PowerShell コマンドの一部としてクラスターの IP アドレスを指定して、PowerShell 経由でクラスターを作成します。
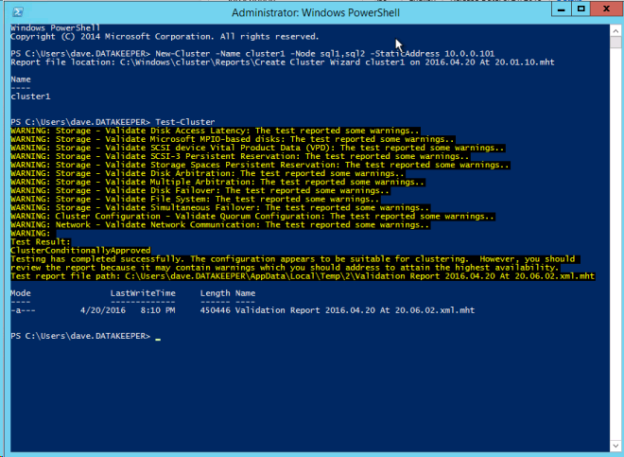
クラスターを作成するには、次のコマンドを実行します。
New-Cluster -Name cluster1 -Node sql1,sql2 -StaticAddress 10.0.0.101
クラスターの作成後、以下のクラスター検証テストを実行します。
Test-Cluster
ファイル共有監視の作成
共有記憶域がないため、2つのクラスターノードと同じ可用性セット内の別のサーバー上にファイル共有監視を作成する必要があります。同じ可用性セットに入れることで、クォーラムからは常に1票しか失われないようにすることができます。 ファイル共有監視の作成方法については、 www.howtonetworking.com/server/cluster12.htm を参照してください。この例では、ファイル共有監視がドメインコントローラー DC1に配置されています。クラスタークォーラムの詳細については、 blogs.msdn.microsoft.com/microsoft_press/2014/04/28/from-the-mvps-understanding-the-windows-server-failover-cluster-quorum-in-windows-server-2012-r2/ を参照してください。
DataKeeper のインストール
インストール時は、全てデフォルトオプションを使用します。
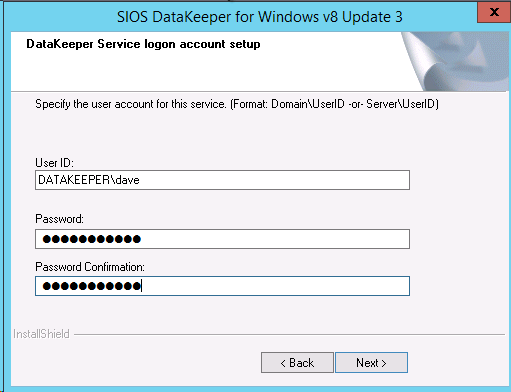
使用するサービスアカウントは、ドメインアカウントである必要があります。また、クラスター内の各ノードのローカル管理者グループに属している必要があります。
DataKeeper が各ノードにインストールされてライセンスが認証されたら、サーバーを再起動します。
DataKeeper ボリュームリソースの作成
DataKeeper ボリュームリソースを作成するには、DataKeeper UI を起動し、両方のサーバーに接続します。
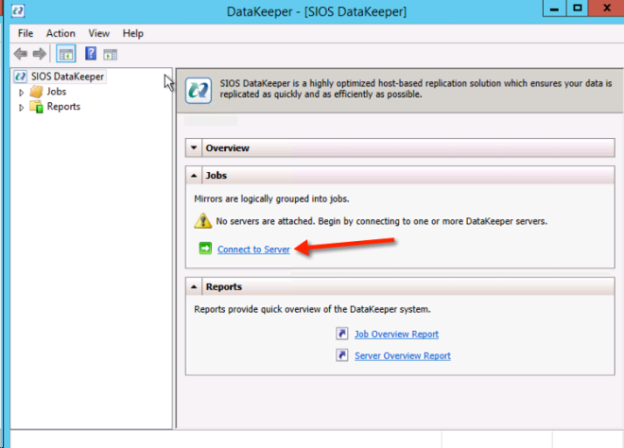
SQL1 に接続します。

SQL2 に接続します。
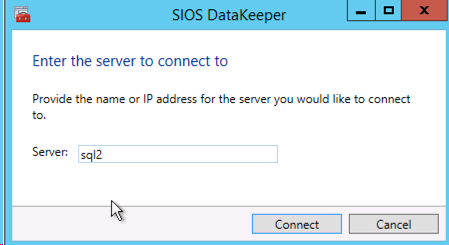
各サーバーに接続したら、ナビゲーション ウィンドウで DataKeeper ボリュームを作成し、 [Jobs] を右クリックして [Create Job] を選択します。
ジョブの名称と説明を追加します。
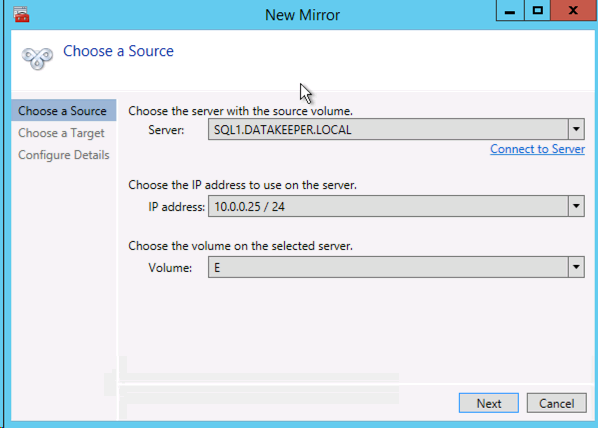
ソースサーバー、IP アドレスおよびボリュームを選択します。選択された IP アドレスによってレプリケーション ネットワークが決まります。
ターゲットサーバーを選択します。
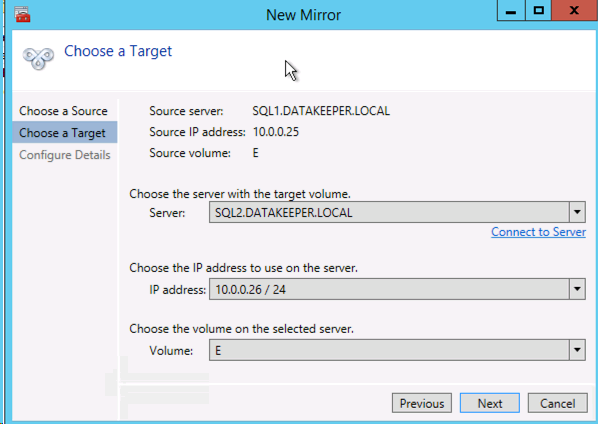
オプションを選択します。2つの VM が同じリージョンにある場合は、同期レプリケーションを使用することを推奨します。長距離レプリケーションでは、データをある程度圧縮する非同期レプリケーションを使用することを推奨します。この例では SQL1と SQL2の両方が同じ地域にあるため、 [Synchronous] (同期)を選択します。
[Yes] をクリックして、新しい DataKeeper ボリュームリソースをフェールオーバークラスタリングの使用可能記憶域に登録します。
新しい DataKeeper ボリュームリソースが使用可能記憶域クラスタグループに表示されます。
1つ目のクラスターノードのインストール
ここで、1つ目のノードをインストールします。クラスターのインストールは、他の SQL クラスターと同じように実施します。 [New SQL Server failover cluster installation] オプションを使用して、1つ目のノードのインストールを開始します。
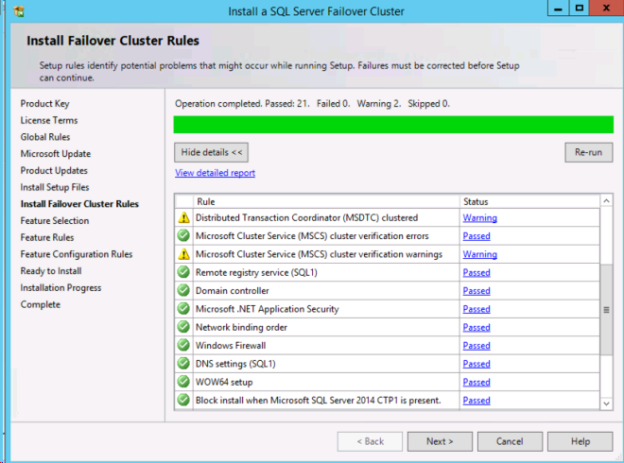

DataKeeper ボリュームリソースは共有ディスクのように、使用可能なディスクリソースとして認識されます。
!https://manula.r.sizr.io/large/user/1870/img/cluster-disk-selection.png
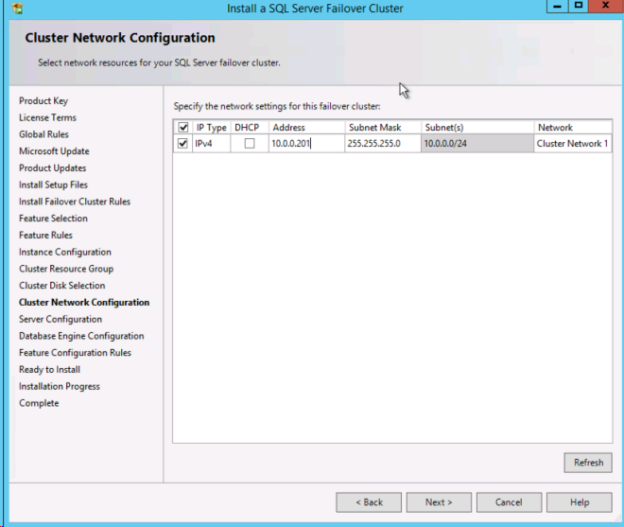
ここで選択する IP アドレスをメモしておきます。これはネットワーク上の一意の IP アドレスである必要があります。このIPアドレスは、後で内部ロード バランサーを作成するときに使用します。
2つ目のノードの追加
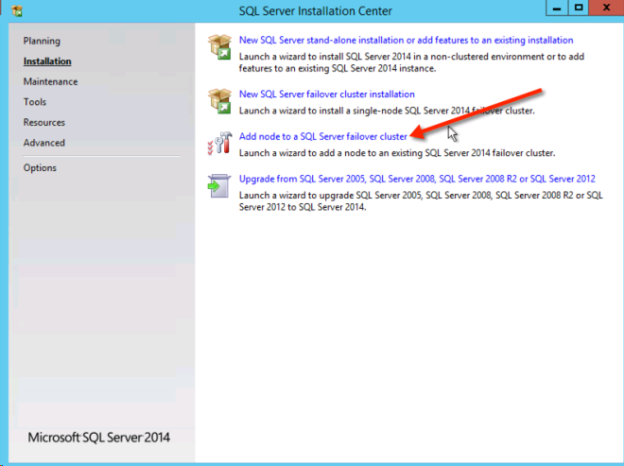
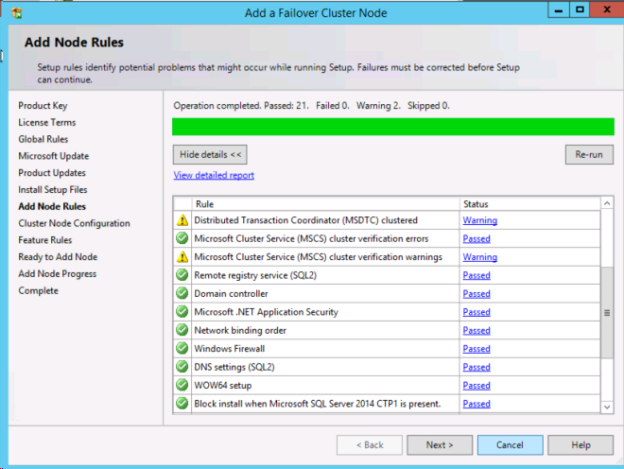
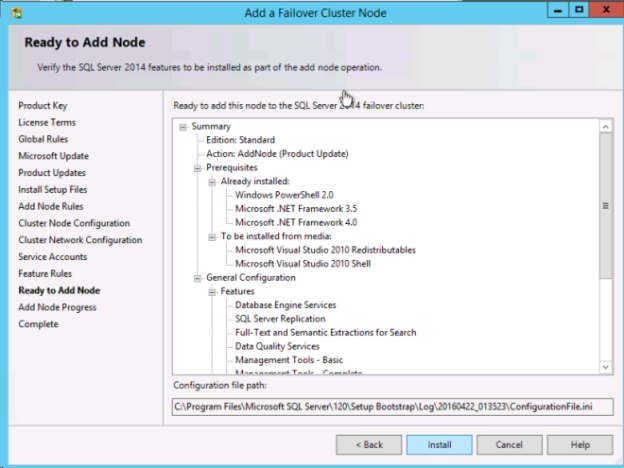
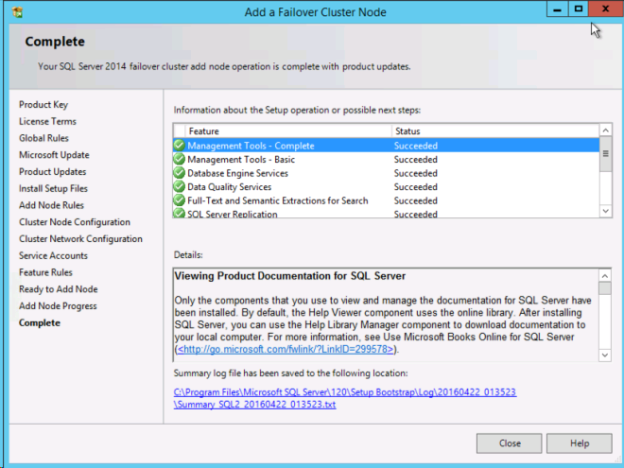
1つ目のノードが正常にインストールされたら、*[Add node to a SQL Server failover cluster]* オプションを使用して2つ目のノードのインストールを開始します。
内部ロード バランサーの作成
Azureのフェールオーバークラスタリングは、従来のインフラストラクチャとは異なります。Azure のネットワーク スタックはGratuitous ARPSをサポートしていないため、クライアントはクラスターの IP アドレスに直接接続できません。代わりに、クライアントはアクティブなクラスターノードにリダイレクトするロード バランサーリソースを介して接続します。よって内部ロード バランサーを作成する必要がありますが、これは以下に示す Azure Portal を使用して作成できます。
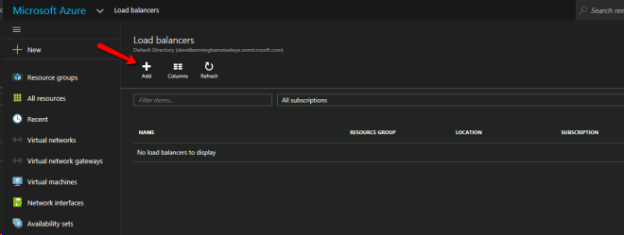
パブリック ロード バランサーは、クライアントがパブリックインターネットに接続する場合に使用できます。クライアントが同じ vNet に存在する場合は、内部ロード バランサーを作成します。仮想ネットワークは、クラスターノードが存在するネットワークと同じでなければなりません。また指定するプライベート IP アドレスは、SQL クラスターリソースの作成に使用したアドレスと完全に一致している必要があります。
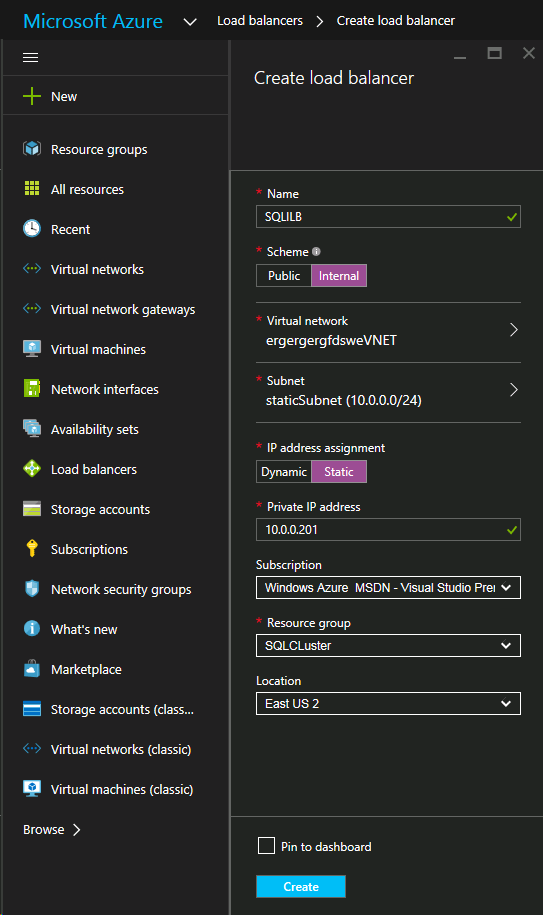
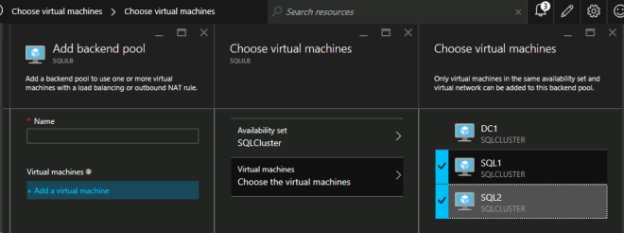
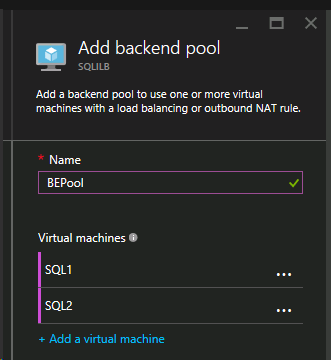
内部ロード バランサー(ILB)の作成後、バックエンドプールを追加します。 このプロセスでは、SQL Cluster VM が存在する可用性セットを選択します。ただし、実際の VM を選択してバックエンドプールに追加する場合は、ファイル共有監視(DC1)をホストする VM を選択しないでください。SQL トラフィックをファイル共有監視にリダイレクトする必要はありません。
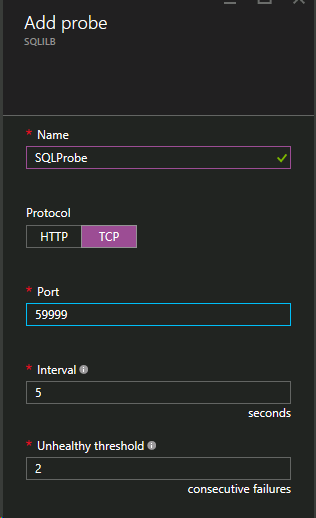
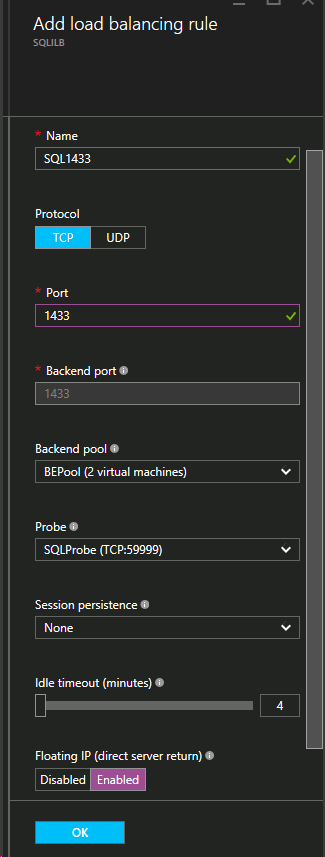
次のステップでは、プローブを追加します。追加するプローブは、ポート59999を監視します。このプローブは、どのノードがクラスター内でアクティブであるかを判別します。
最後に、SQL Server トラフィックをリダイレクトするための負荷分散ルールが必要です。SQL のデフォルトのインスタンスはポート1433を使用します。アプリケーション要件に応じて、1434などに対してルールを追加できます。フローティング IP (Direct Server Return) は [有効] にします。
SQL Server IP リソースの修正
最後のステップでは、クラスターノード1つで以下の PowerShell スクリプトを実行します。これにより、クラスター IP アドレスが ILB プローブに応答し、クラスター IP アドレスと ILB との間に IP アドレスの競合がないことを確認できます。
注記: 環境に合わせてこのスクリプトを編集する必要があります。サブネットマスクは255.255.255.255に設定されていますが、間違いではありませんのでこのままにします。これにより、ILB との IP アドレスの競合を避けるためのホスト固有のルートを作成します。
# Define variables
$ClusterNetworkName = “”
# the cluster network name (Use Get-ClusterNetwork on Windows Server 2012 of higher to find the name)
$IPResourceName = “”
# the IP Address resource name
$ILBIP = “”
# the IP Address of the Internal Load Balancer (ILB)
Import-Module FailoverClusters
# If you are using Windows Server 2012 or higher:
Get-ClusterResource $IPResourceName | Set-ClusterParameter -Multiple @
{Address=$ILBIP;ProbePort=59999;SubnetMask=“255.255.255.255”;Network=$ClusterNetworkName;EnableDhcp=0}
# If you are using Windows Server 2008 R2 use this:
#cluster res $IPResourceName /priv enabledhcp=0 address=$ILBIP probeport=59999 subnetmask=255.255.255.255
このトピックへフィードバック