
This section provides information regarding issues that may be encountered with the use of DataKeeper for Linux. Where appropriate, additional explanation of the cause of an error is provided along with necessary action to resolve the error condition.
Messages specific to DataKeeper for Linux can be found in the DataKeeper Message Catalog. Messages from other SPS components are also possible. In these cases, please refer to the Combined Message Catalog which provides a listing of all error codes, including operational, administrative and GUI, that may be encountered while using SIOS Protection Suite for Linux and, where appropriate, provides additional explanation of the cause of the error code and necessary action to resolve the issue. This full listing may be searched for any error code received, or you may go directly to one of the individual Message Catalogs for the appropriate SPS component.
The following table lists possible problems and suggestions.
| Symptom | Suggested Action |
|---|---|
| Warning message that netraid mirror does not have a unique identifier. |
The configuration should be modified as soon as possible to use a unique identifier. The recommended steps to repair are: 1. Start with LifeKeeper running on all nodes. 2. Identify unsafe netraid resources and the underlying disks for each resource on each node. It is important to do this on each node as the mapping may be DIFFERENT on each node. # ins_list -r netraid -f: | grep DEVNAME | grep -v mapper | cut -f4,5 -d: NOTE: This is the list of netraid “tag:ID”. In the following instructions the device name mapping matching above is assumed. 3. Check if device is configured with GPT. For each device run the GPT getId: #/opt/LifeKeeper/lkadm/subsys/scsi/gpt/bin/getId -i /dev/xvdb 4. If getId returns a unique ID then update the instance: #ins_setid -t datarep-test1 -i “4757cd62-e065-4013-8514-1031b446aa24” <If there are any devices that are not GPT then continue with Step 5> 5. Identify resources that depend on the unsafe netraid resources. # ins_list -r netraid -f: | grep DEVNAME | grep -v mapper | cut -f4 -d: | while read entry; do dep_list -p $entry -f: 2>/dev/null | cut -f1 -d:; done NOTE: this is the list of tags for the file systems associated with the netraid devices. 6. Identify the mount points for the file system. Typically the tag for the file system resource is the same as the mount point. If that is not the case you can match the file system tag with the file system mount point using: # ins_list -t filesys3 -f: | cut -d: -f5 7. Stop all activity leaving only the file system resources in-service on netraid devices. a. Take all resources out-of-service. Follow the steps below only for the devices that are unsafe. 8. Backup all data on affected file systems where the resources are in-service. 9. Take all resources out-of-service on all cluster nodes. 10. Backup the LifeKeeper configuration (lkbackup -c —cluster). 11. Delete the hierarchy with each unsafe netraid resource. a. Take note of the hierarchy, what application is affected is being deleted. 12. At this point, the only things left are resources that do not have dependencies with unsafe netraid resources. In most cases that should be the IP resources, EC2 resources, etc. 13. Run lkstop on all nodes. 14. Verify all affected file systems are unmounted. 15. Reconfigure devices on each node with a GPT partition table (using gdisk, parted, etc) or use LVM. 16. Start LifeKeeper on all nodes. 17. Create new Replicated file systems for each file system, extending each resource to all nodes. • /dev/xvdb1 -> /test1 18. Restore data from the backup to each mount point. The data will automatically resync to the target(s). 19. Recreate application hierarchies deleted in step 11. Please refer to the SIOS Product Documentation for details on DataKeeper storage configuration options. |
| After primary server panics, DataKeeper resource goes ISP on the secondary server, but when primary server reboots, the DataKeeper resource becomes OSF on both servers. | Check the “switchback type” selected when creating your DataKeeper resource hierarchy. Automatic switchback is not supported for DataKeeper resources in this release. You can change the Switchback type to “Intelligent” from the resource properties window. |
| DataKeeper GUI wizard does not list a newly created partition. | The Linux OS may not recognize a newly created partition until the next reboot of the system. View the /proc/partitions file for an entry of your newly created partition. If your new partition does not appear in the file, you will need to reboot your system. |
| Errors during failover | Check the status of your device. If resynchronization is in progress you cannot perform a failover. |
| Error creating a DataKeeper hierarchy on currently mounted NFS file system | You are attempting to create a DataKeeper hierarchy on a file system that is currently exported by NFS. You will need to replicate this file system before you export it. |
| Extending to a target does not prompt for “Replication Type” to allow setting asynchronous or synchronous. | When the mirror was created, “no” was selected for “Enable Asynchronous Replication.” Delete the mirror and recreate selecting “yes” to “Enable Asynchronous Replication” when prompted. |
| NetRAID device not deleted after DataKeeper resource deletion. | Deleting a DataKeeper resource will not delete the NetRAID device if the NetRAID device is mounted. You can manually unmount the device and delete it by executing: mdadm –S <md_device> (cat /proc/mdstat to determine the <md_device>). |
| Primary server cannot bring the resource ISP when it reboots after both servers became inoperable. | If the primary server becomes operable before the secondary server, you can force the DataKeeper resource online by opening the resource properties dialog, clicking the Replication Status tab, clicking the Actions button, and then selecting Force Mirror Online. Click Continue to confirm, then Finish. |
| Replication Type is asynchronous instead of synchronous. Replication between two systems was initially configured for asynchronous replication, but synchronous replication is required instead. | Unextend the mirror and extend again, selecting “synchronous” when prompted for the connection. |
| Replication Type is synchronous instead of asynchronous. Replication between two systems was initially configured for synchronous replication, but asynchronous replication is required instead. | Unextend the mirror and extend again, selecting “asynchronous” when prompted for the connection. |
| Resources appear green (ISP) on both primary and backup servers. | This is a “split-brain” scenario that can be caused by a temporary communications failure. After communications are resumed, both systems assume they are primary. DataKeeper will not resync the data because it does not know which system was the last primary system. Manual intervention is required. If not using a bitmap: You must determine which server was the last backup, then take the resource out of service on that server. DataKeeper will then perform a FULL resync. If using a bitmap: You must determine which server was the last backup, then take the resource out of service on that server. DataKeeper will then perform a partial resync. |
| Target(s) are out of sync waiting for the previous source. | Connect the previous source to the cluster. If the previous source can not rejoin the cluster in a timely manner, then targets can be reconnected with a full resync by running the command “$LKROOT/bin/mirror_action fullresync <source> <target>” on the current mirror source. |
| Core – Language Environment Effects | Some LifeKeeper scripts parse the output of Linux system utilities and rely on certain patterns in order to extract information. When some of these commands run under non-English locales, the expected patterns are altered and LifeKeeper scripts fail to retrieve the needed information. For this reason, the language environment variable LC_MESSAGES has been set to the POSIX “C” locale (LC_MESSAGES=C) in /etc/default/LifeKeeper. It is not necessary to install Linux with the language set to English (any language variant available with your installation media may be chosen); the setting of LC_MESSAGES in /etc/default/LifeKeeper will only influence LifeKeeper. If you change the value of LC_MESSAGES in /etc/default/LifeKeeper, be aware that it may adversely affect the way LifeKeeper operates. The side effects depend on whether or not message catalogs are installed for various languages and utilities and if they produce text output that LifeKeeper does not expect. |
| GUI – GUI login prompt may not re-appear when reconnecting via a web browser after exiting the GUI | When you exit or disconnect from the GUI applet and then try to reconnect from the same web browser session, the login prompt may not appear. Workaround: Close the web browser, re-open the browser and then connect to the server. When using the Firefox browser, close all Firefox windows and re-open. |
| DataKeeper Create (and Extend) Resource fails | When using DataKeeper in certain environments (e.g., virtualized environments with IDE disk emulation, servers with HP CCISS storage, solid state devices (SSD), or Amazon EBS storage), an error may occur when a mirror is created: 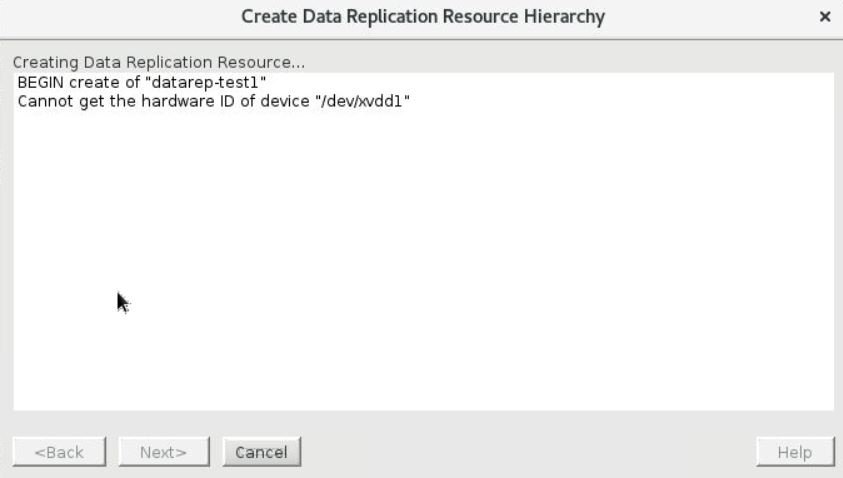 This is because LifeKeeper does not recognize the disk in question and cannot get a unique ID to associate with the device. Workaround: Create a GUID partition and assign a unique ID to the partition or use LVM. |
| The status of the mirror target becomes “Out of Sync” after upgrading | The use of an NU device is not recommended for LifeKeeper 9.2.2 or later. A “mirror out of sync” problem occurs in environments where DataKeeper resources are configured with NU devices. When upgrading to LifeKeeper 9.2.2 or later, add the following settings to /etc/default/LifeKeeper if NU devices are used: LKDR_ALLOW_NU=TRUE How to check whether NU devices are used: Run the lcdstatus command. If a resource instance ID field contains a character string beginning with NU-, then NU devices are used. |
Post your comment on this topic.