
A “split brain” scenario occurs when the SAP HANA database is running and configured as the primary SAP HANA Replication site on multiple cluster nodes. In this situation, LifeKeeper will suspend all monitoring of the HANA database until the issue is manually resolved by a database administrator.
There are two common types of split brain scenarios which may occur for an SAP HANA resource hierarchy.
- LifeKeeper HANA Resource Split Brain: The HANA resource is Active (ISP) in LifeKeeper on multiple cluster nodes. This situation is typically caused by a temporary network outage affecting the communication paths between cluster nodes.
- SAP HANA System Replication Split Brain: The HANA resource is Active (ISP) on the primary node and Standby (OSU) on the backup node in LifeKeeper, but the database is running and registered as the primary replication site on both nodes. This situation is typically caused by either a failure to stop the database on the previous primary node during failover, having Autostart enabled for the database, or a database administrator manually running “hdbnsutil -sr_takeover” on the secondary replication site outside of LifeKeeper.
Recommendations for resolving each type of split brain scenario are given below.
LifeKeeper HANA Resource Split Brain Resolution
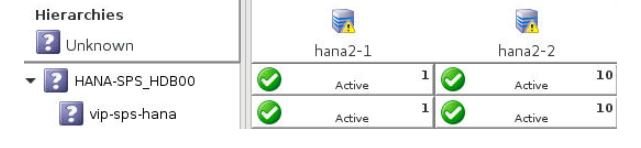
While in this split brain scenario, a message similar to the following is logged and broadcast to all open consoles every quickCheck interval (default 2 minutes) until the issue is resolved.
EMERG:hana:quickCheck:HANA-SPS_HDB00:136363:WARNING: A temporary communication failure has occurred between servers hana2-1 and hana2-2. Manual intervention is required in order to minimize the risk of data loss. To resolve this situation, please take one of the following resource hierarchies out of service: HANA-SPS_HDB00 on hana2-1 or HANA-SPS_HDB00 on hana2-2. The server that the resource hierarchy is taken out of service on will become the secondary SAP HANA System Replication site.
Recommendations for resolution:
- Investigate the database on each cluster node to determine which instance contains the most up-to-date or relevant data. This determination must be made by a qualified database administrator who is familiar with the data.
- The HANA resource on the node containing the data that needs to be retained will remain Active (ISP) in LifeKeeper, and the HANA resource hierarchy on the node that will be re-registered as the secondary replication site will be taken entirely out of service in LifeKeeper. Right-click on each leaf resource in the HANA resource hierarchy on the node where the hierarchy should be taken out of service and click Out of Service …
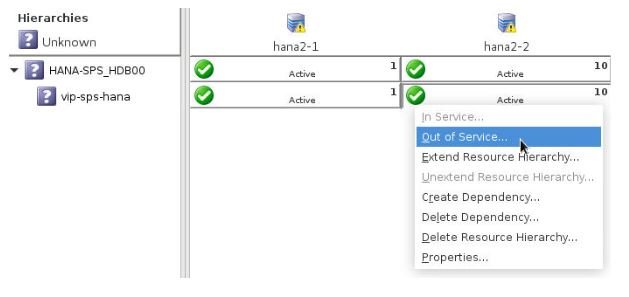
- Once the SAP HANA resource hierarchy has been successfully taken out of service, LifeKeeper will re-register the Standby node as the secondary replication site during the next quickCheck interval (default 2 minutes). Once replication resumes, any data on the Standby node which is not present on the Active node will be lost. Once the Standby node has been re-registered as the secondary replication site, the SAP HANA hierarchy has returned to a highly-available state.
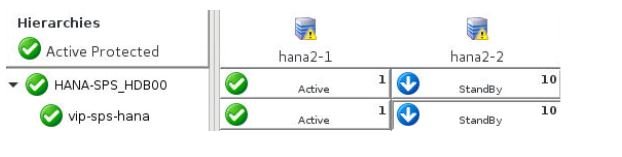
SAP HANA System Replication Split Brain Resolution
While in this split brain scenario, a message similar to the following is logged and broadcast to all open consoles every quickCheck interval (default 2 minutes) until the issue is resolved.
EMERG:hana:quickCheck:HANA-SPS_HDB00:136234:WARNING: SAP HANA database HDB00 is running and registered as primary master on the following servers: hana2-2, hana2-1. Manual intervention is required in order to minimize the risk of data loss. To resolve this situation, please stop database HDB00 on the standby server by running the command ‘su – spsadm -c “sapcontrol -nr 00 -function StopWait 600 5”’ on that server, allow LifeKeeper to register the standby server as a secondary replication site, then use LifeKeeper to bring resource HANA-SPS_HDB00 in-service on the intended primary replication site.
Recommendations for resolution:
- Investigate the database on each cluster node to determine whether important data exists on the Standby node which does not exist on the Active node. If important data has been committed to the database on the Standby node while in the split brain state, the data will need to be manually copied to the Active node. This determination must be made by a qualified database administrator who is familiar with the data.
- Once any missing data has been copied from the database on the Standby node to the Active node, stop the database on the Standby node by running the command given in the LifeKeeper warning message:
su - <sid>adm -c "sapcontrol -nr <Inst#> -function StopWait 600 5"
where <sid> is the lower-case SAP System ID for the HANA installation and <Inst#> is the instance number for the HDB instance (e.g., the instance number for instance HDB00 is 00).
- Once the database has been successfully stopped, LifeKeeper will re-register the Standby node as the secondary replication site during the next quickCheck interval (default 2 minutes). Once replication resumes, any data on the Standby node which is not present on the Active node will be lost. Once the Standby node has been re-registered as the secondary replication site, the SAP HANA hierarchy has returned to a highly-available state and may be brought in-service on any server in the cluster.
SAP HANA Multitarget Split Brain Recovery
When a split brain occurs in a multitarget configuration one server that has the HANA resource in-service may also be connected to and synchronized with the standby target. If the server that IS connected and in-sync with the standby target is the one selected to remain in-service then LifeKeeper will automatically connect and synchronize with the node that is taken out-of-service. This is the preferred recovery.
If, however, the node selected to remain in-service is not connected to the standby target then when LifeKeeper tries to remote register the database on the standby target, it may fail. In that case, the standby target may require manually unregistering the remote replication site. This will then allow LifeKeeper to register the database but SAP HANA will probably initiate a full resync to the target.
The following command will show the HANA connections.
su - spsadm -c "python /usr/sap/SPS/HDB00/exe/python_support/systemReplicationStatus.py --sapcontrol=1"
If hana2-2 is not connected to the standby target its output would look like this:
hana2-2# su - spsadm -c "python /usr/sap/SPS/HDB00/exe/python_support/systemReplicationStatus.py --sapcontrol=1" SAPCONTROL-OK: <begin> site/2/REPLICATION_MODE=PRIMARY site/2/SITE_NAME=SiteA local_site_id=2 SAPCONTROL-OK: <end> hana2-2#
If hana2-1 is connected to hana2-3:
hana2-1# su - spsadm -c "python /usr/sap/SPS/HDB00/exe/python_support/systemReplicationStatus.py --sapcontrol=1" SAPCONTROL-OK: <begin> service/ip-12-0-0-237/30001/DATABASE=SYSTEMDB service/ip-12-0-0-237/30001/HOST=hana2-1 service/ip-12-0-0-237/30001/PORT=30001 service/ip-12-0-0-237/30001/SERVICE_NAME=nameserver service/ip-12-0-0-237/30001/VOLUME_ID=1 service/ip-12-0-0-237/30001/SITE_ID=1 : : site/2/SITE_NAME=SiteD site/2/SOURCE_SITE_ID=1 site/2/REPLICATION_MODE=ASYNC site/2/REPLICATION_STATUS=UNKNOWN overall_replication_status=UNKNOWN site/1/REPLICATION_MODE=PRIMARY site/1/SITE_NAME=SiteC local_site_id=1 site/2/SECONDARY_FULLY_SYNCED=False overall_in_sync_status=SYSTEM_NOT_IN_SYNC SAPCONTROL-OK: <end> hana2-1#
hana2-3# su - spsadm -c "python /usr/sap/SPS/HDB00/exe/python_support/systemReplicationStatus.py --sapcontrol=1" SAPCONTROL-OK: <begin> site/2/REPLICATION_MODE=ASYNC site/2/SITE_NAME=SiteD site/2/SOURCE_SITE_ID=1 site/2/PRIMARY_MASTERS=hana2-1 local_site_id=2 SAPCONTROL-OK: <end> hana2-3#
If hana2-2 is taken out-of-service as shown above then LifeKeeper will be able to register the database and a partial resync will occur. If hana2-1 is taken out-of-service instead then hana2-2 will be able to register hana2-1 but will probably NOT be able to register hana2-3 requiring manual intervention to unregister hana2-3.
The GUI will show the status of hana2-3 as “Standby – Unknown HSR Status” or “Standby – HSR Error” and the ReplicationStatus.py output shown above will continue to show the “site/2/PRIMARY_MASTERS=hana2-1” instead of hana2-2. To allow LifeKeeper on hana2-1 to register hana2-3 the database must first be unregistered:
hana2-3# su - spsadm -c "hdbnsutil -sr_unregister"
unregistering site ...
done.
hana2-3#
The state of the resource on hana2-3 will transition to “Standy – HSR Disabled”, then “Standby – Initializing”, “Standby – Syncing”, and finally “Standby – In Sync”. This may cause a full resync to hana2-3.
Post your comment on this topic.