
This configuration replicates data between sites where each site utilizes shared storage.
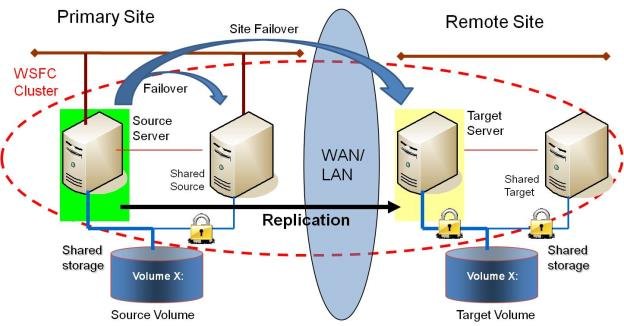
Steps to be replicated from the picture above:
- Create a shared volume between the first two nodes within the “Primary Site”.
- Storage (Shared Volume) 1 should be presented to servers A and B (Source and Target) – the volume will show up in disk manager, but will be locked/offline on the secondary server.
- Repeat this process for the 2 servers on the remote site.
- Lastly, Create the cluster and data replication between both servers.
Note: DataKeeper should identify the storage being shared and make the required changes to the configuration.
Note that the number of systems in the Primary Site does not have to equal the number of systems in the Remote Site.
Also note that only the Source Server has access to the Source Volume. Shared Source systems and all systems on the target side cannot access the volume and are locked from the file system’s perspective.
| Example: USE CASE |
Users who wish to provide the same level of availability in their DR site will deploy this configuration to ensure that regardless of what site is in service, the availability level stays the same. |
|---|---|
| Example: USE CASE |
Where Hyper-V clusters are configured with virtual machines distributed across many cluster nodes, it is important to have a similar number of cluster nodes available in the disaster recovery sight to ensure that the resources are available to run all of the virtual machines in the event of a disaster. |
Additional topics of interest include:
Post your comment on this topic.